


Data structures is an important topic in software development and not very easy when you are getting started. Today we will go through the common data structures in JavaScript and try to understand them most simply.
Before you continue further, read my articles about What is the Difference Between Data Type and Data Structure & JavaScript Data Types.
What is data structure?
In computer science, a data structure is a collection of data types that can be organized in different ways which are related to each other and on which we can perform different actions to manipulate this data.
Even if you are a beginner in programming I am sure you have already interacted with arrays or objects which are data structures as well.
As the name suggests, structure means that the data can be structured in different ways and there is not just one type of structure but multiple.
Let’s explore each of them to understand how they are structured and what we can do with them!
#1 Array
An array is the most basic data structure in JavaScript which holds some data for later use. An array is something like a train with a container where each container can hold only one value. Arrays in JavaScript can hold different data types at the same time while in some languages it’s not possible. This means that you can have numbers and strings in the same array at the same time.
Each position in the array has its index, the indication where its location — it’s something like a postal code for each item in the array. Index in JavaScript starts with 0 meaning that the first item’s index is 0, the second’s 1, and so on.

An array has different methods which can manipulate data. For example, you can use pop() to remove the very last element or push() to add elements at the end of the array.
Finally, an array also has a property to check its length, which is called simply length (e.g. someArray.length).

Using an array is great for very simple, minimalistic lists however it’s very weak when it comes to the stability of indices. When you add new items to the start or middle of the array, the index of all items changes so it’s not very good in some cases when you depend on the index and it’s not stable.
#2 Objects
An object in JavaScript is another data structure that you will see a lot, really a lot! An object is a data structure that consists of the key-value pair collection. This type of data structure that consists of key-value pairs is also called Hash Table, Map, or Dictionary depending on the programming language.
To create an object you use curly braces instead of square brackets compared to an array. Then a key name and a value are separated with a colon. A key-value can be any data type like string, number, boolean, array, and even an object.
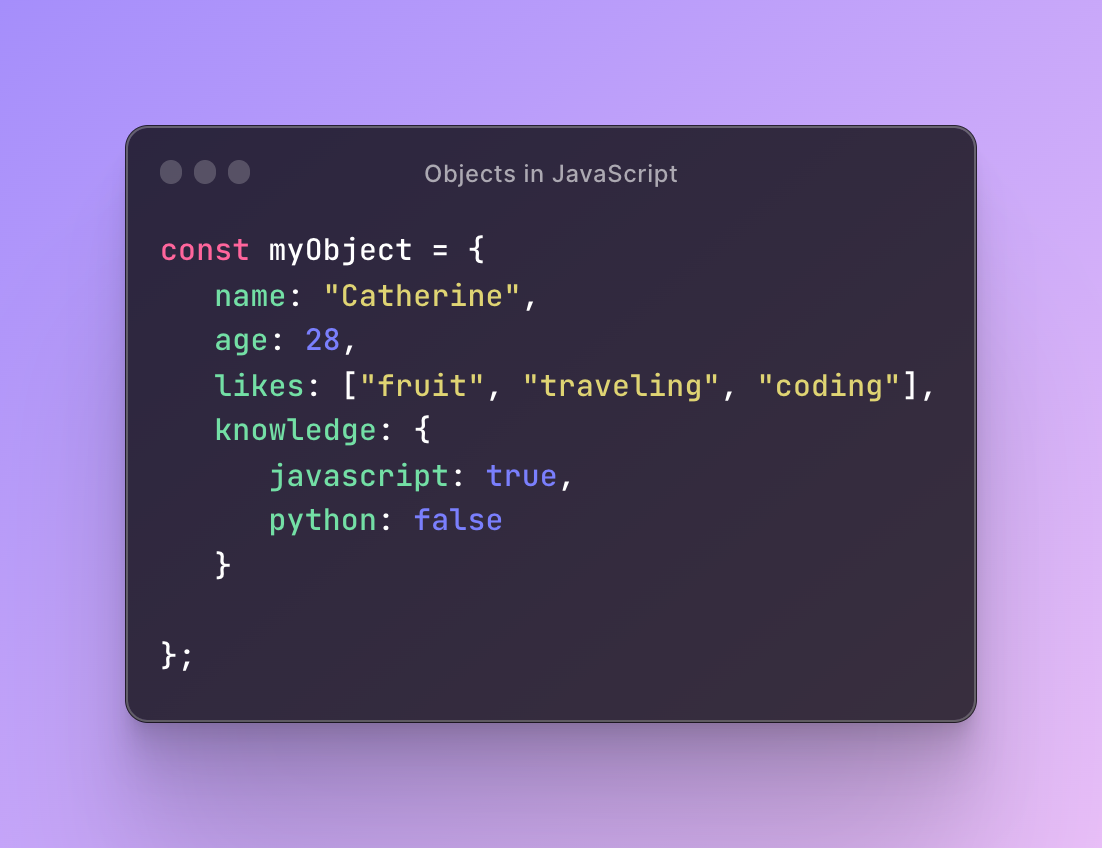
The objects cannot have keys with the same name and objects can also have functions that are called methods while the other key-value names are called properties when comes to objects.
Just like arrays, an object always has different built-in methods like entries() that return an array of key-value pairs.
#3 Hash Table
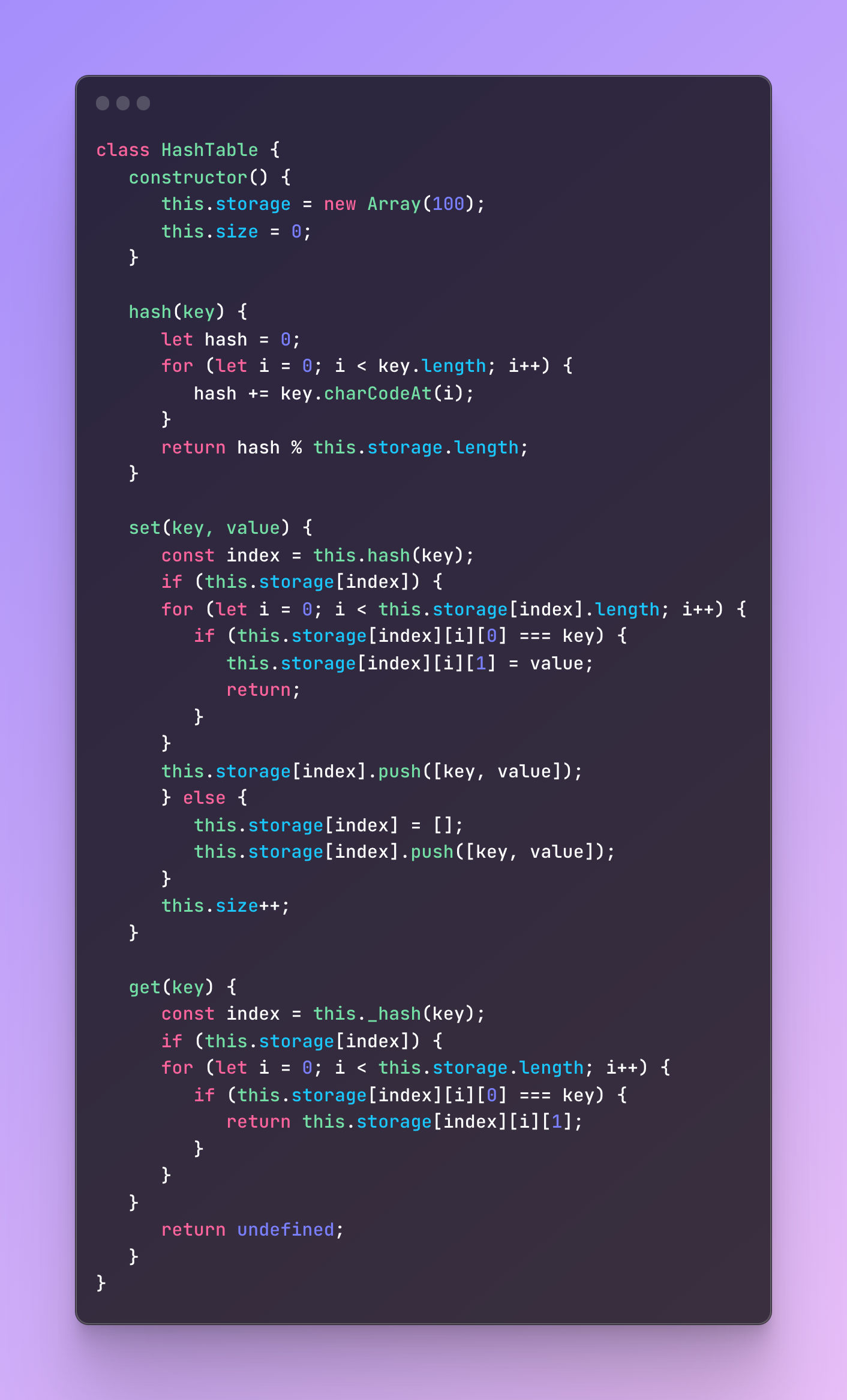
A hash table is a data structure similar to objects which is a collection of key-value pairs. It’s also often named an associative array in JavaScript. A hash table secretly transforms the key-value into a number (which is also called a hash) with a so-called hash function. Then this number is paired with the value which is stored storage bucket.
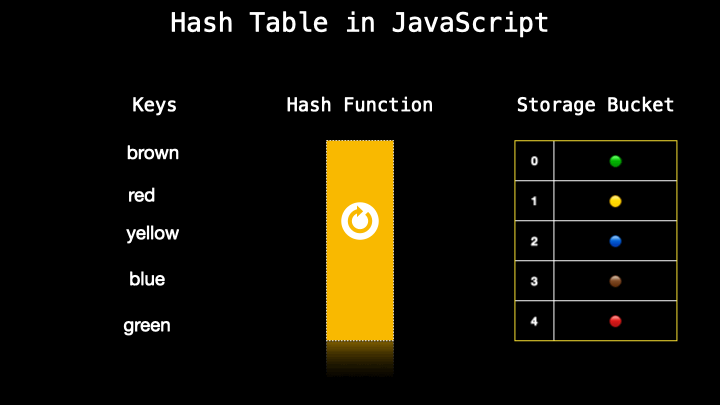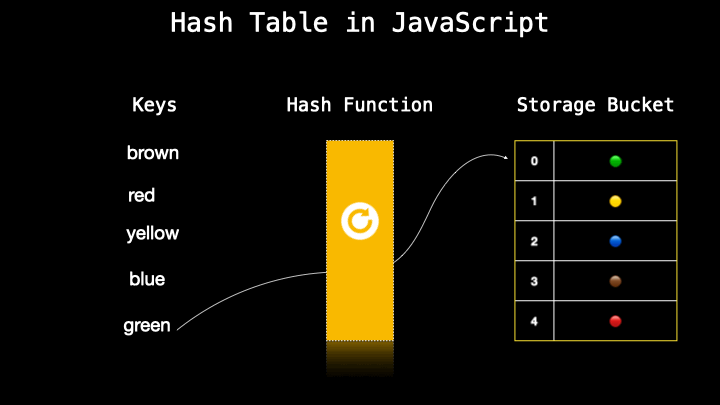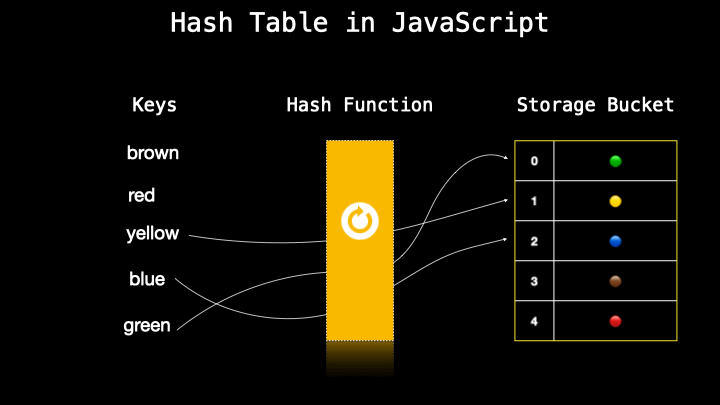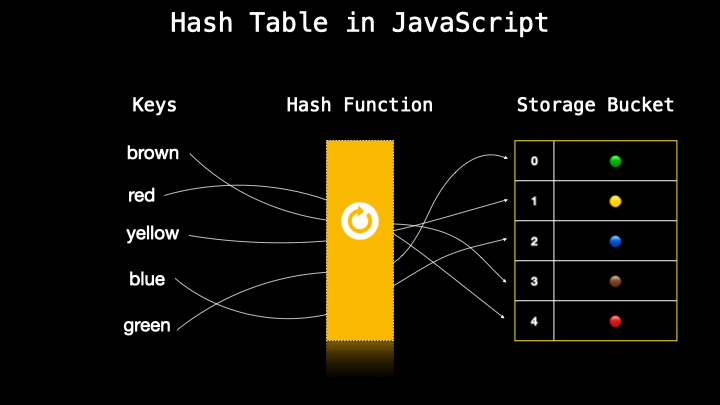
As I mentioned previously, a hash table is often the same as the object in other languages however there is no actual hash table in JavaScript so we just implement that by using different approaches where one of them is using an object to create a hash table.
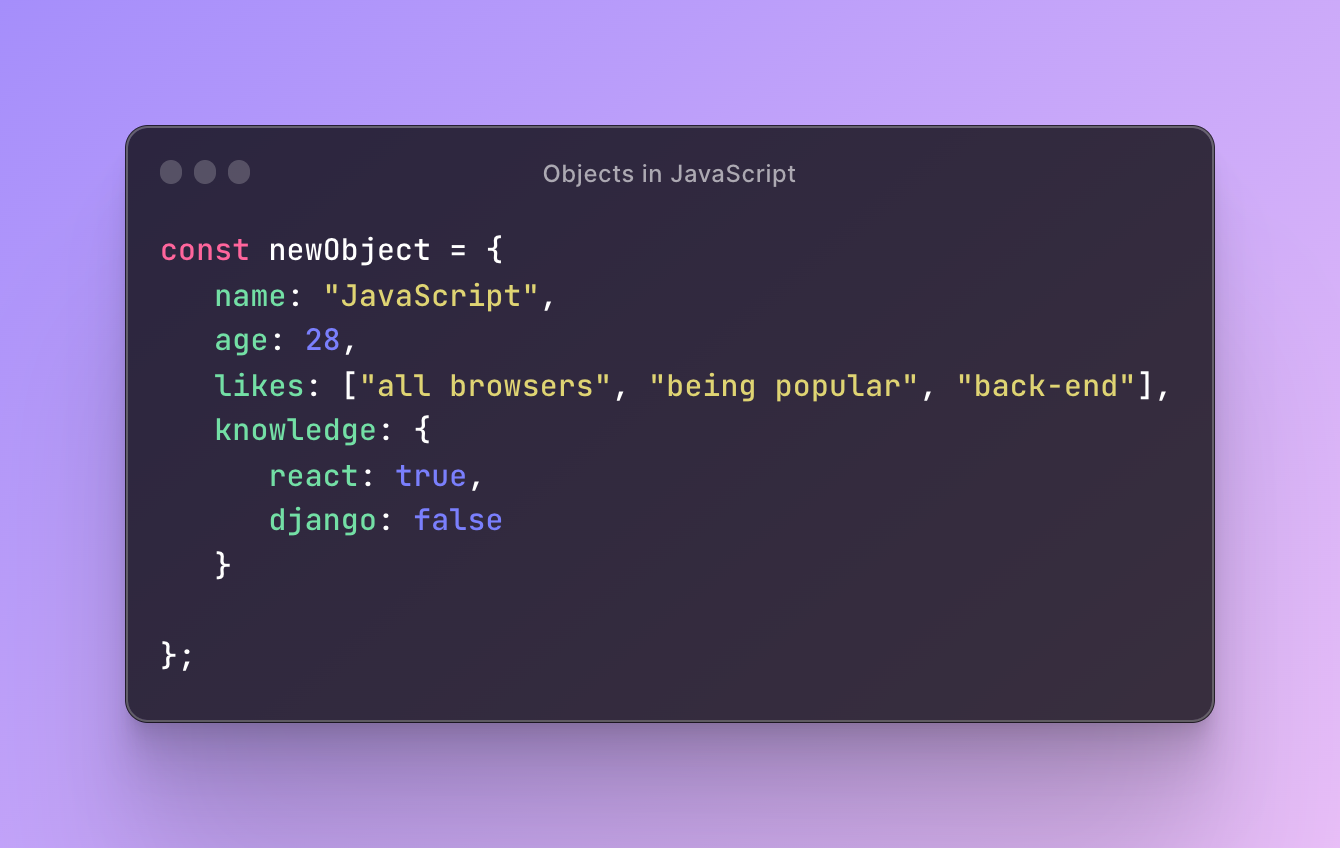
Creating a hash table with an object
To create a hash table with an object you simply create an object just like we did previously.
So you can use a regular object as a hash table but this is not the best approach. Why? Because JavaScript objects are hard to track when it comes to size and have to do some manipulations to achieve that. In general, objects are hard to be optimized when it comes to frequent key-value changes. Also, there is a chance of collisions because two keys might convert to the same hash or two hashes might point to the same value. Finally, object keys can be only a string or symbol type.
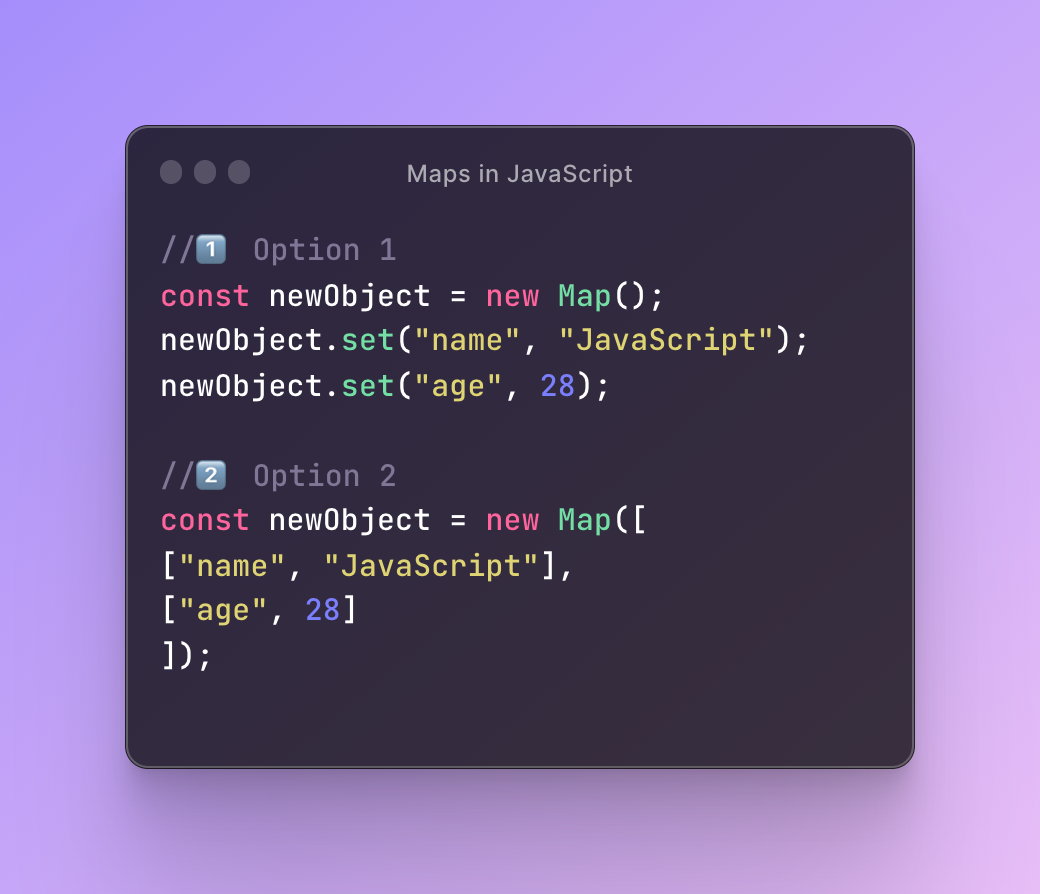
Creating a hash table with a map
A map is another object type that remembers the insertion order of the keys and it’s also a collection of key-value pairs, just like an object. Compared to a regular object, however, maps have a size property. Also, there are no pre-existing keys that might cause a collision and it’s more optimized for key-value insertions.
A map can also have different properties like delete, get, set, or clear that can delete, get, add key and/or value, or remove all of them. However, a map still inherits the properties we don’t need and a map is still not the best option.
Your implementation of a hash table
Finally, the most common practice is creating your implementation of a hash table as both object and map are not the best options.
✅ Hash table implementation checklist:
Create a call with storage and size properties
Add a hash function to transform a key into an index
Add a set method to add key-value pairs
Add a get method to retrieve key-value pairs
#1 Create a call with storage and size properties
The storage in this case refers to the storage bucket I have mentioned previously.
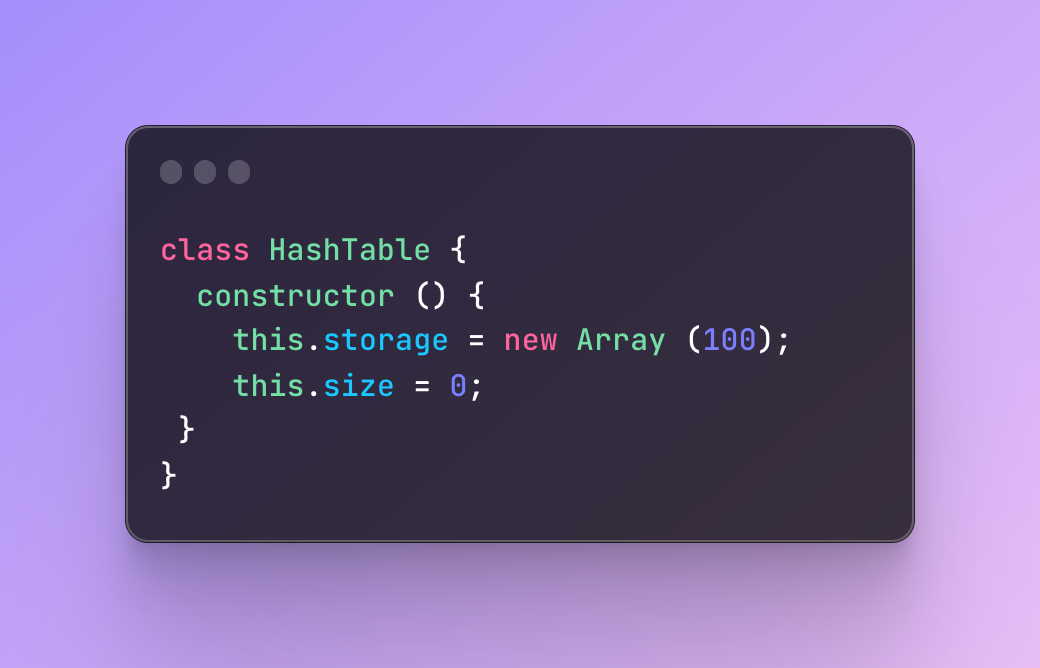
#2 Add a hash function to transform a key into an index
I also mentioned previously that in a hash table, the key is transformed into an index number which is also called a hash and that’s what we want to achieve with a hash function.
Inside a hash function, we are going to loop through the key, take each character, and transform this character into an integer by using a string method charCodeAt.
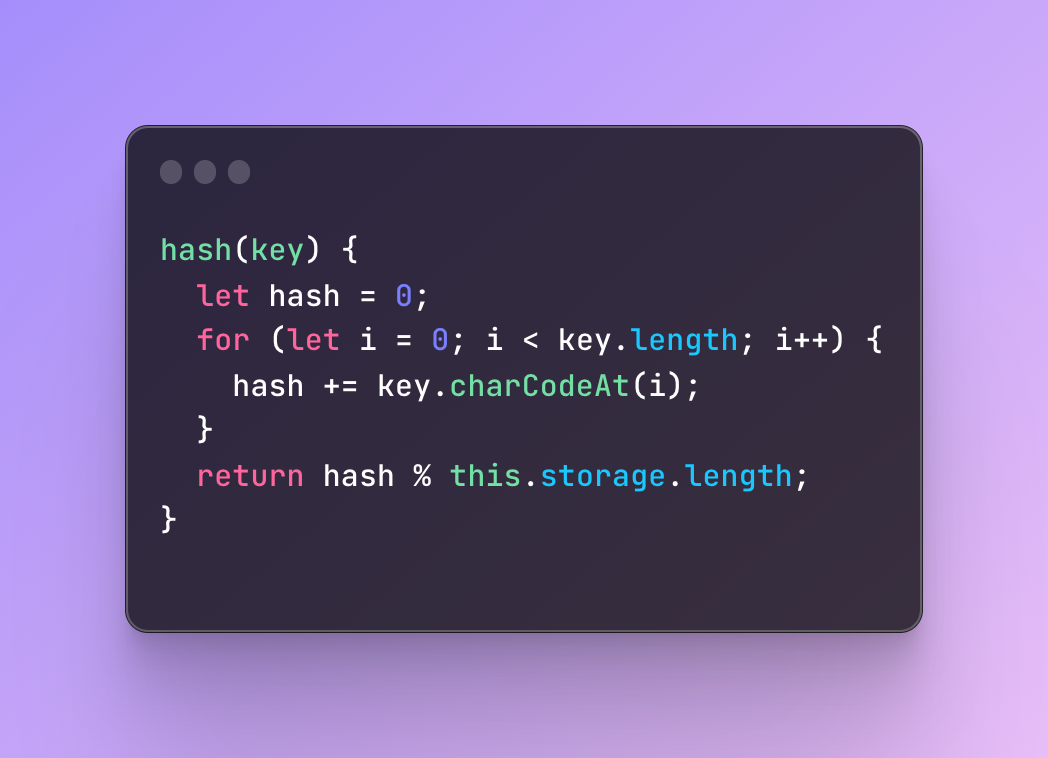
What we are doing here is that we take the key, loop through each letter/character of this key, transforming each of them into an integer by using a string method CharCodeAt and sum all of them.
Finally, we don’t return just a number we got from the sum but also make sure that this number is not going to be more than the storage capacity.
#3 Add a set method to add key-value pairs
The main of the set method is to find the index of the key-value pair and retrieval of this index is going to happen with the help of the hash function we created previously — the one which converts our key to an index.
Then we are going to move this key-value pair to our storage at the index we received from the hash function.
Finally, we are going to increase the size property of the storage to make sure that the current size will not exceed the storage.
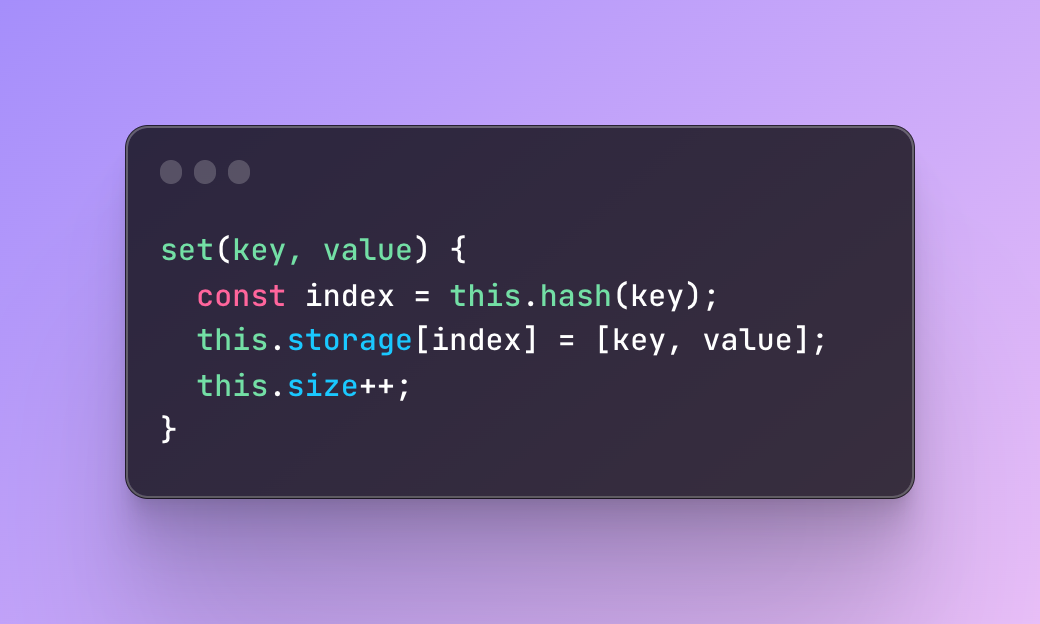
Looks easy, right? However, this is not enough!
As we discussed the main issue with objects or maps when it comes to the hash table is that indices can collide.
The hash function we wrote is not good enough because what if we have a key with the same name but different values? What will happen is that both keys will change to the same number as both consist of the same letters.
As a result, they both will return the same index.
To avoid this we will need a little better set function as well as a get function.
What we will change is that we will add some if else statements and check if the storage already contains a similar key and if it does will store the new key-value pair in a different array.
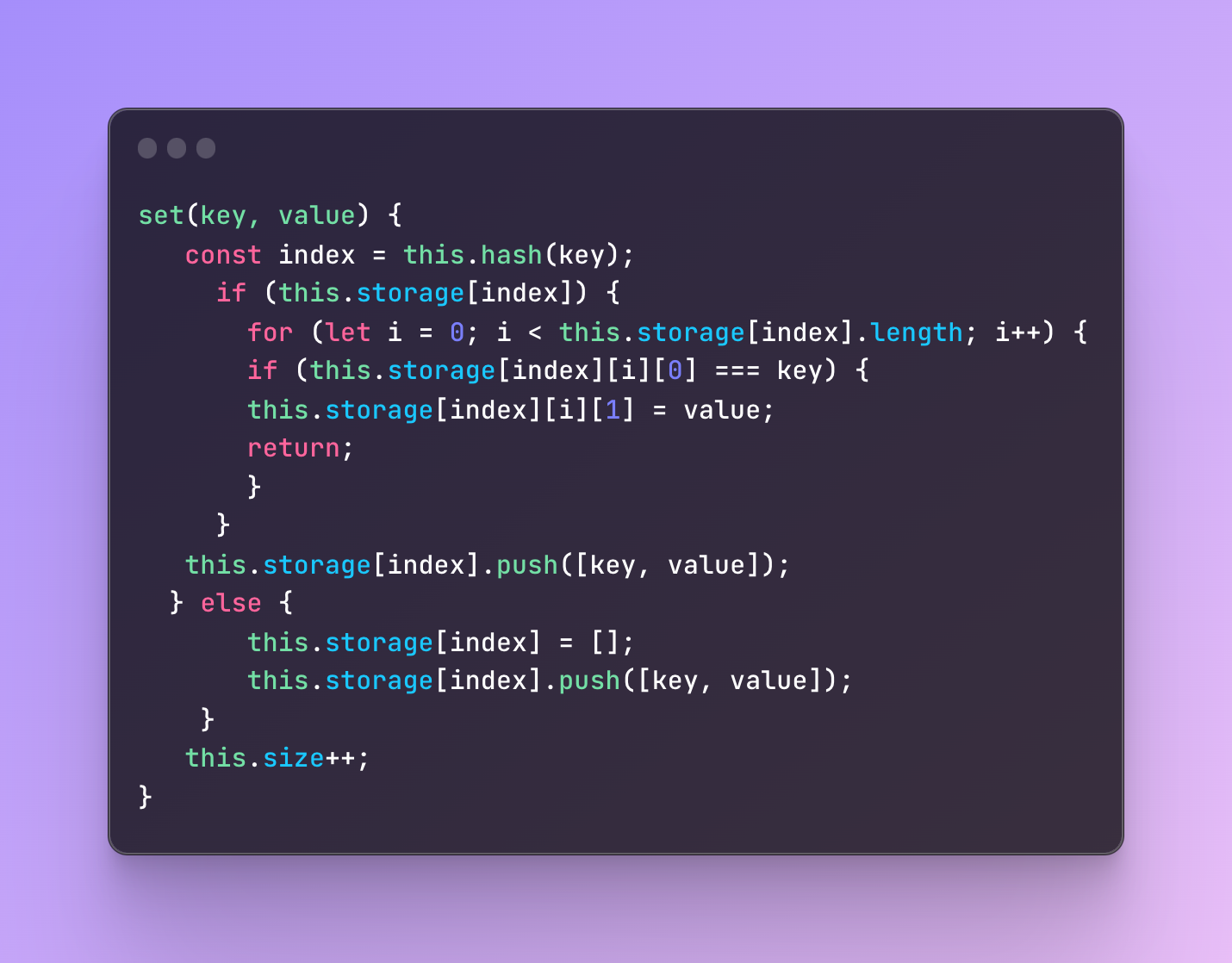
Looks confusing, right?
Let’s go through each step to understand what is going on.
If the key-value pair located at the index we received from the hash function exists start looping at the index 0 but stop when you reach the length of the array at that index.
For example, we start with index 0, choose the first array, take its key which is at index 0, and check if this key equals the new key we passed to the set method.
If it’s the same then at we target the value of that key located at index 1, replace it, and stop the execution. If no match of the key is found then push the value to the second array.
So what we are trying to do is that if for some reason any keys are converted to the same number and they might end up at the same index, we will make sure they are located in separate arrays but still at the same array.
Otherwise, if the index is not occupied and we didn’t find anything there we simply push the key-value pair like we usually do.
#4 Add a get method to retrieve key-value pairs
Finally, we are going to create a get method to retrieve the values by passing a key, getting the index by using a hash function, and returning the key-value pair from the storage by indicating the index, simple as that.
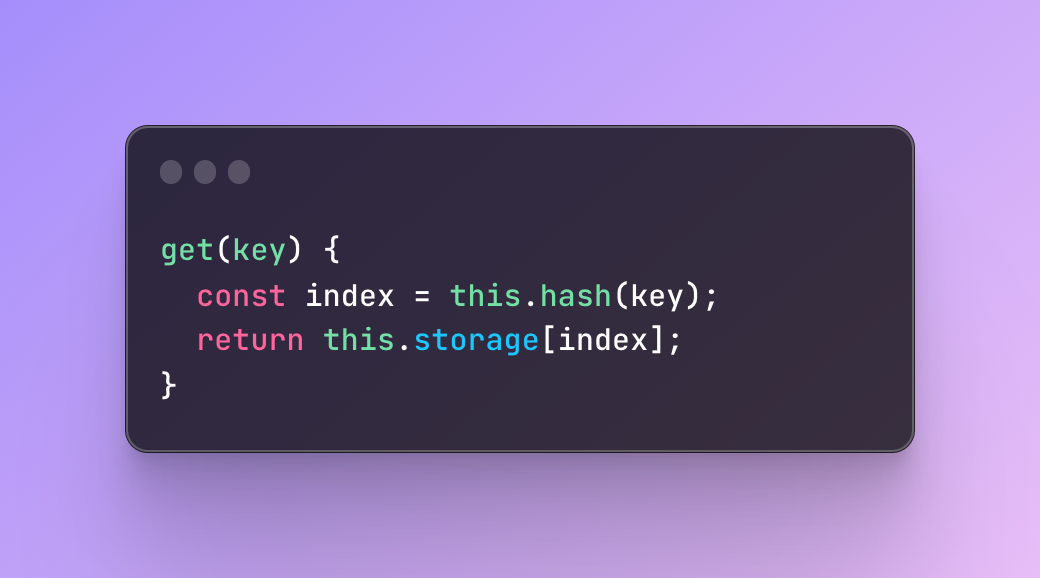
However, if we decided to create a second-level array with the set method which makes sure that key-value pairs with the same index but different keys do not collide, we will also need a different get method which also checks the arrays located deeper.
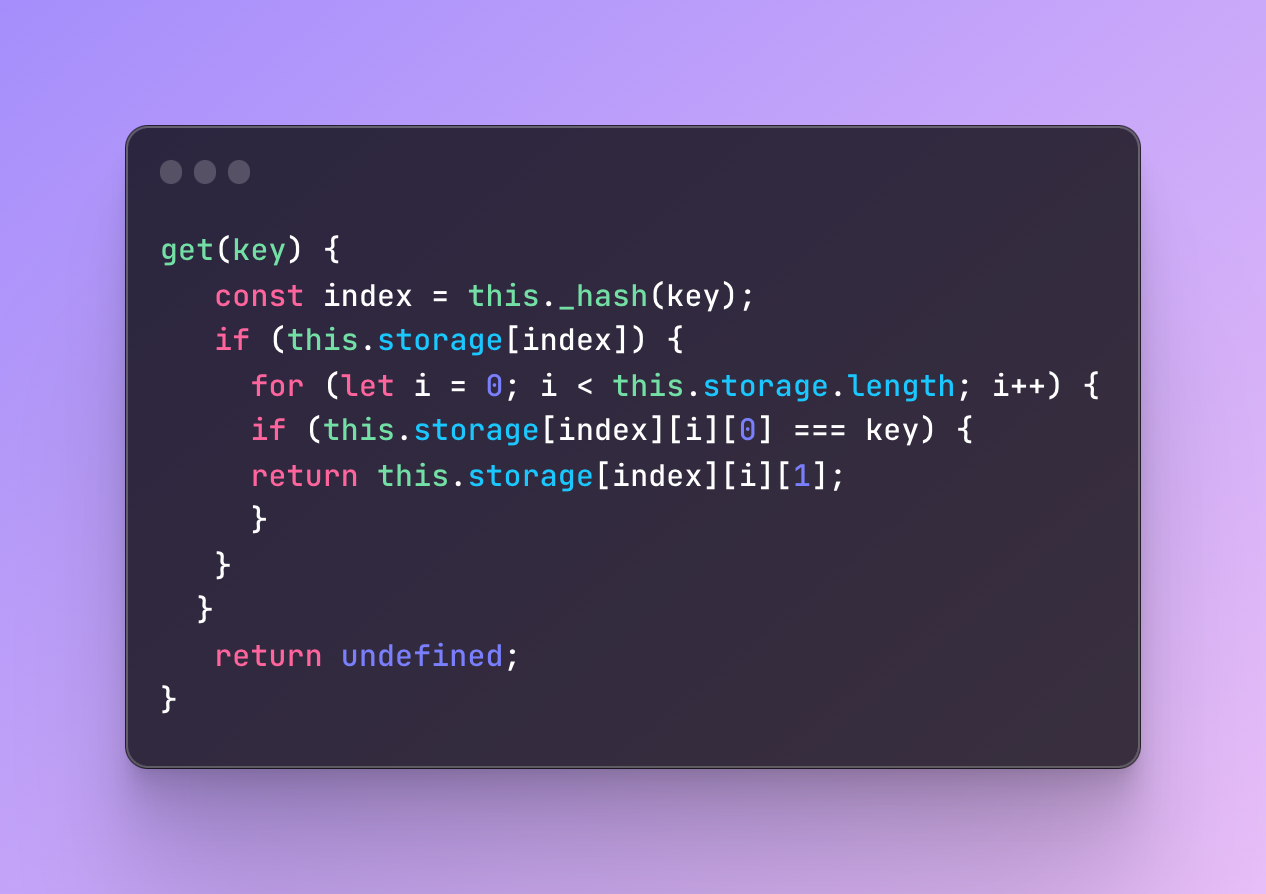
We are done with creating a hash table and this is the final result. There are a lot of other things that you can add and improve, like removing the key-value pairs, for instance, however, we will do it again later.
#4 Stacks
Stack as the name suggests is a data structure where data is stacked on top of each other. Imagine a stack of books, paper, blocks, and so on.
Stack follows a principle which is called last in, first out aka LIFO. This means that the way data is structured in the stack doesn’t let you randomly change data from anywhere you want and the only possible way is the very end of the stack (or top of the stack).
For example, if you want to add a book that is located before the very last book, you cannot just insert it right into the specific position. First, you need to remove the last one and only then add the book. So the very last book will be the very first which will be out — last in, first out.

Stack is often used in things like undo/redo, for instance, where we can go back and forth in history but cannot jump over specific actions.
Stack has different methods like push which add new elements at the end, pop which removes the very last element, and peek which returns the last element and length to check the length of the stack.
Stack is also not available in JavaScript however we can construct it ourselves just like we did with hash.
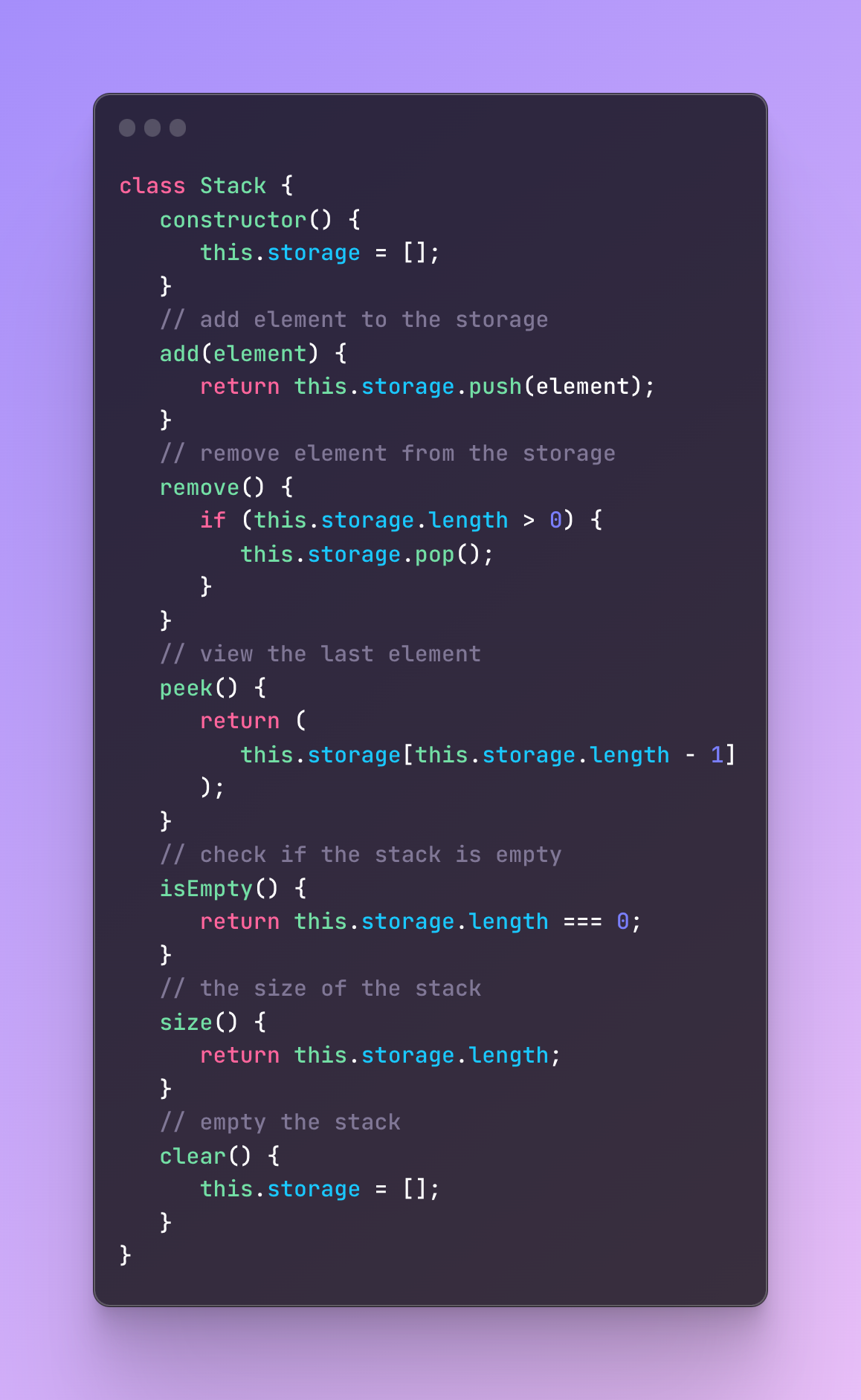
Let’s understand better what is going on here.
First, we create a class with variable storage that is going to serve as an array where we add or remove values.
The add method in this class is used to add an element at the end of the stack.
The remove method removes the last element in the array.
The peek views the last element.
The isEmpty method checks if the stack is empty.
The size checks the size of the array and the clear makes the stack empty.
#5 Queue
Queues are similar to stack but there is some difference. I guess you understand that structure of a queue is just like a regular queue we know, for example, a supermarket queue.
But imagine if you were standing in a queue, it would be inconvenient if it worked with a stack pattern LIFO (last in, first out). It means that the last person in the queue would be the first to leave the queue, doesn’t make any sense, right?
In queues, data cannot be added or removed just in any order but the pattern it follows is called first in, first out (FIFO) which means that when in a queue the very first person in will be the very first that will be out. So the data is processed by the recent one entered.
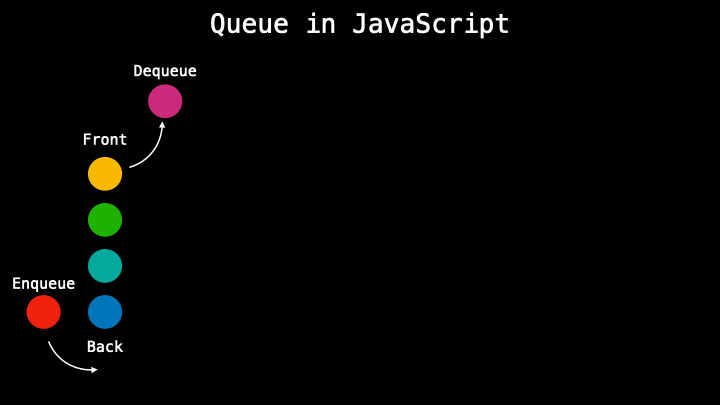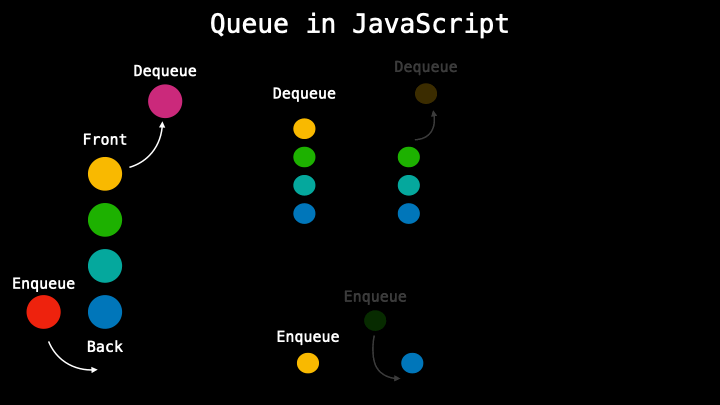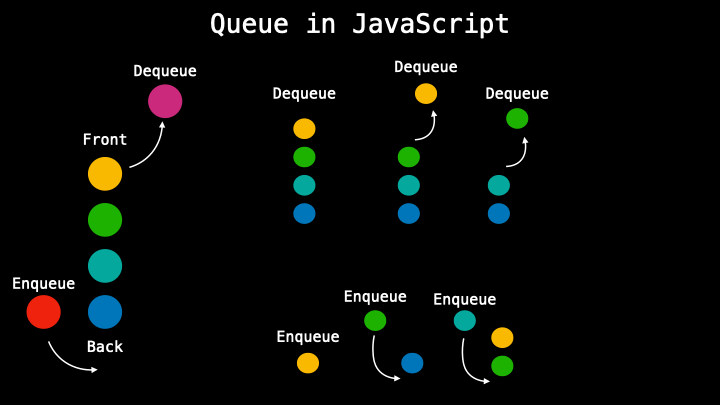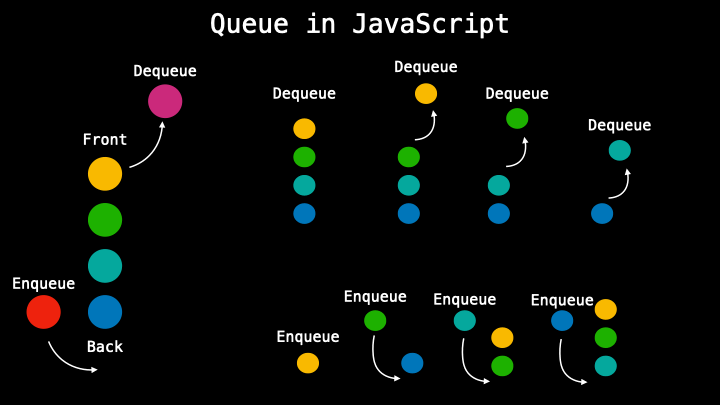
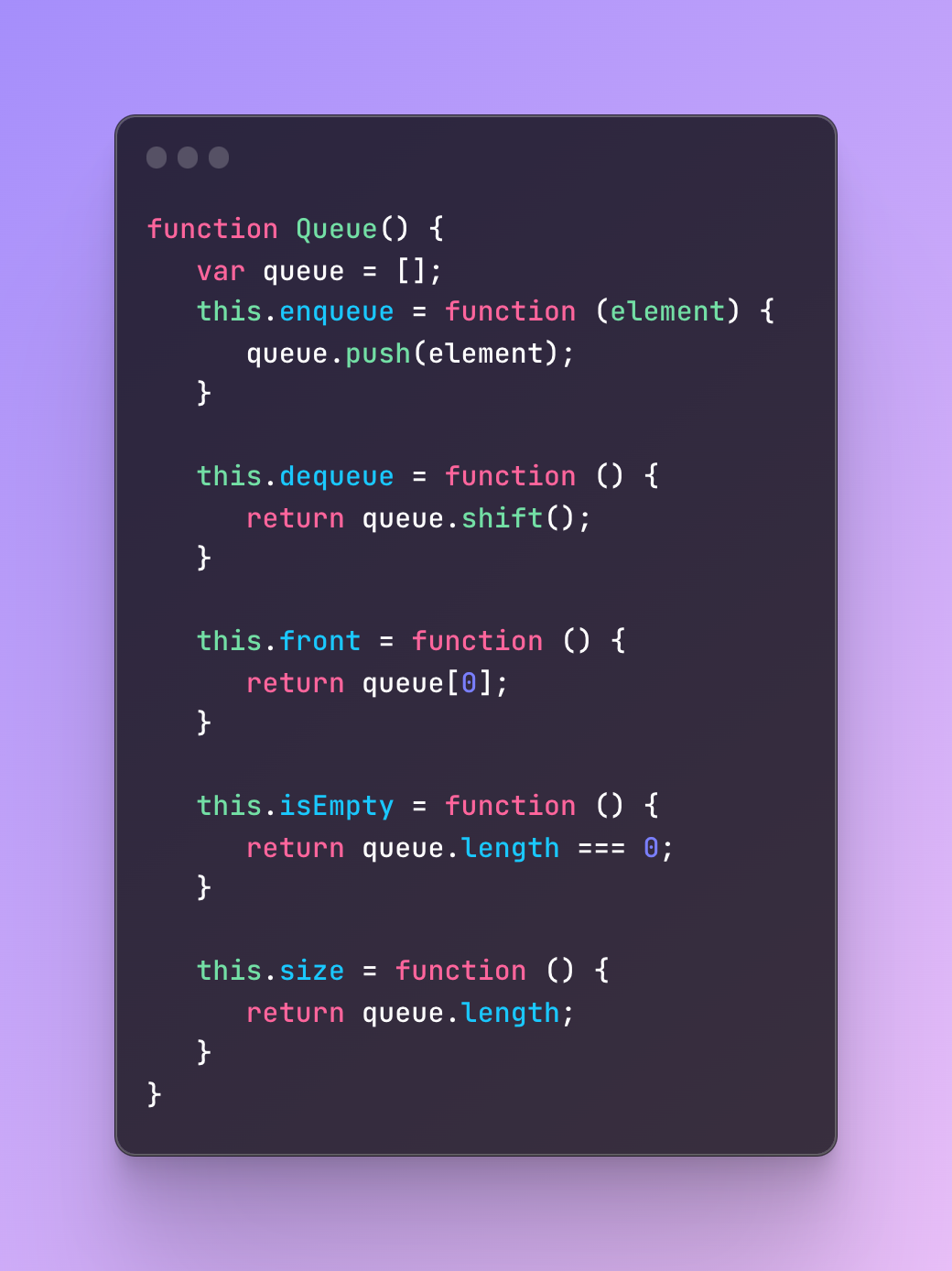
There are different methods in a queue like a dequeue when removing the first element, enqueue adding a new element at the end, a front to get the first element in the queue, or size to get the size of the queue.
Just like stack or hash, there is no actual implementation of it but we can create one ourselves.
#6 Linked List
A linked list is a data structure that holds data in form of a list or chained data where each item is called a node. Each node in the list can have a value but also pointers. These pointers point to the next or previous node and that way they create a link between nodes.
A linked list can be either a singly linked list or a doubly linked list. A singly linked list has one type of pointer in the node which points only to the next node but doubly has two pointers where the other one points to the previous node as well.
The first element is also called the head and the last one is called the tail. The last elements are equal to null as they don’t point to anything anymore.

Linked lists are similar to arrays but have some differences. For example, compared to arrays lists don’t have indexes, and values are known with the help of pointers.
This also means that values cannot be accessed randomly and we have to iterate through it from start or end. This makes it possible to insert or delete data from any part of the list and you don’t have to manipulate only the last or first element.
I guess you already guessed that we have to implement linked lists ourselves with different methods like pop, push, shift, get, set, insert, and so on. There are many different methods when it comes to linked lists.
Let’s create a linked list with JavaScript functions.
First, we create a node that consists of a value and a pointer

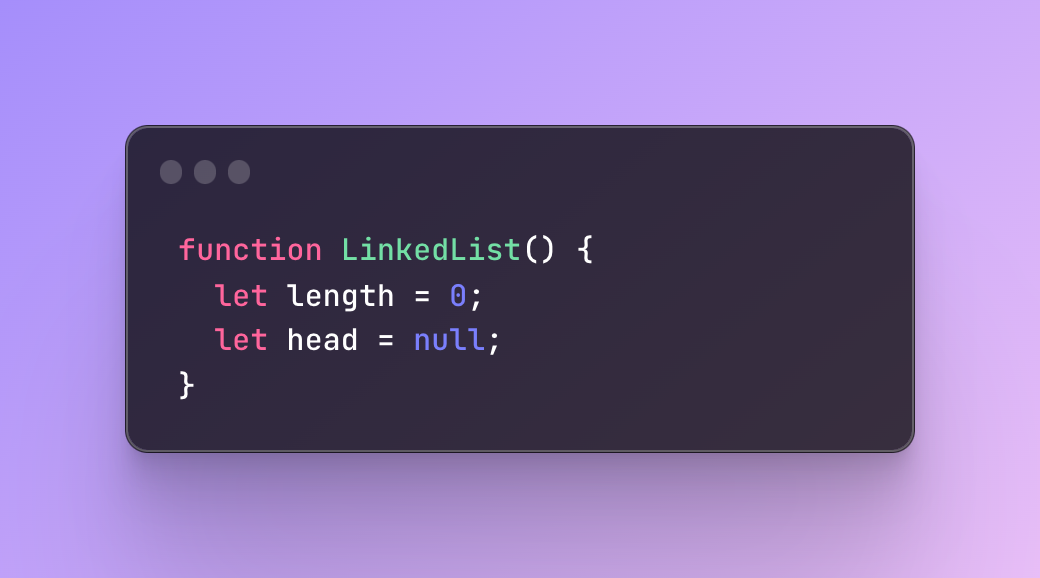
Next, we create a linked list function with two variables — length and head.
And then we can start implementing different methods that linked lists usually have. All these methods will be placed inside the function of the linked list so you can call them whenever you need to manipulate data inside this linked list.
To find the size of the linked list we can create a function size that returns the length variables that will eventually change once we add elements.
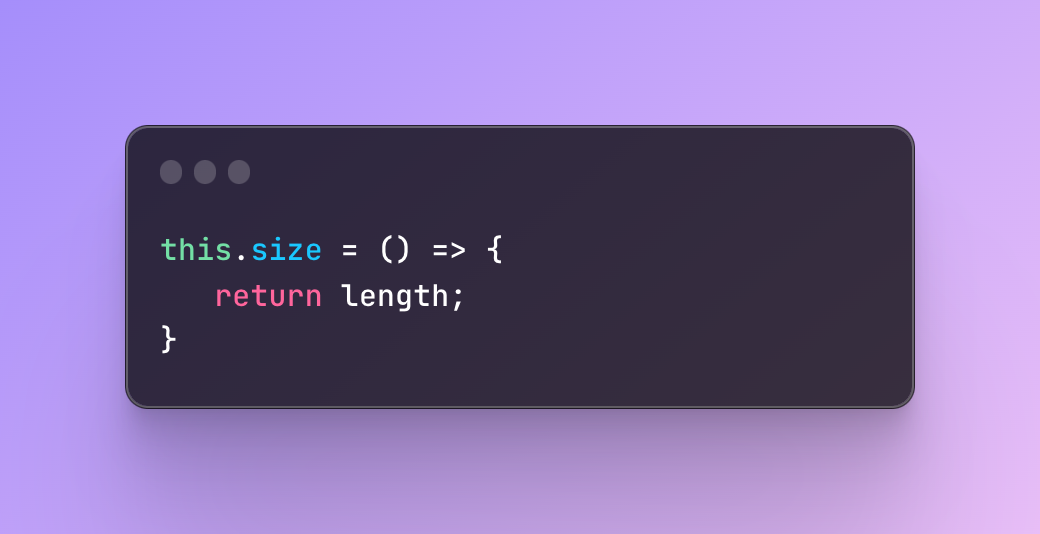
Next, we will create a function that returns a head, the very first node in the linked list.

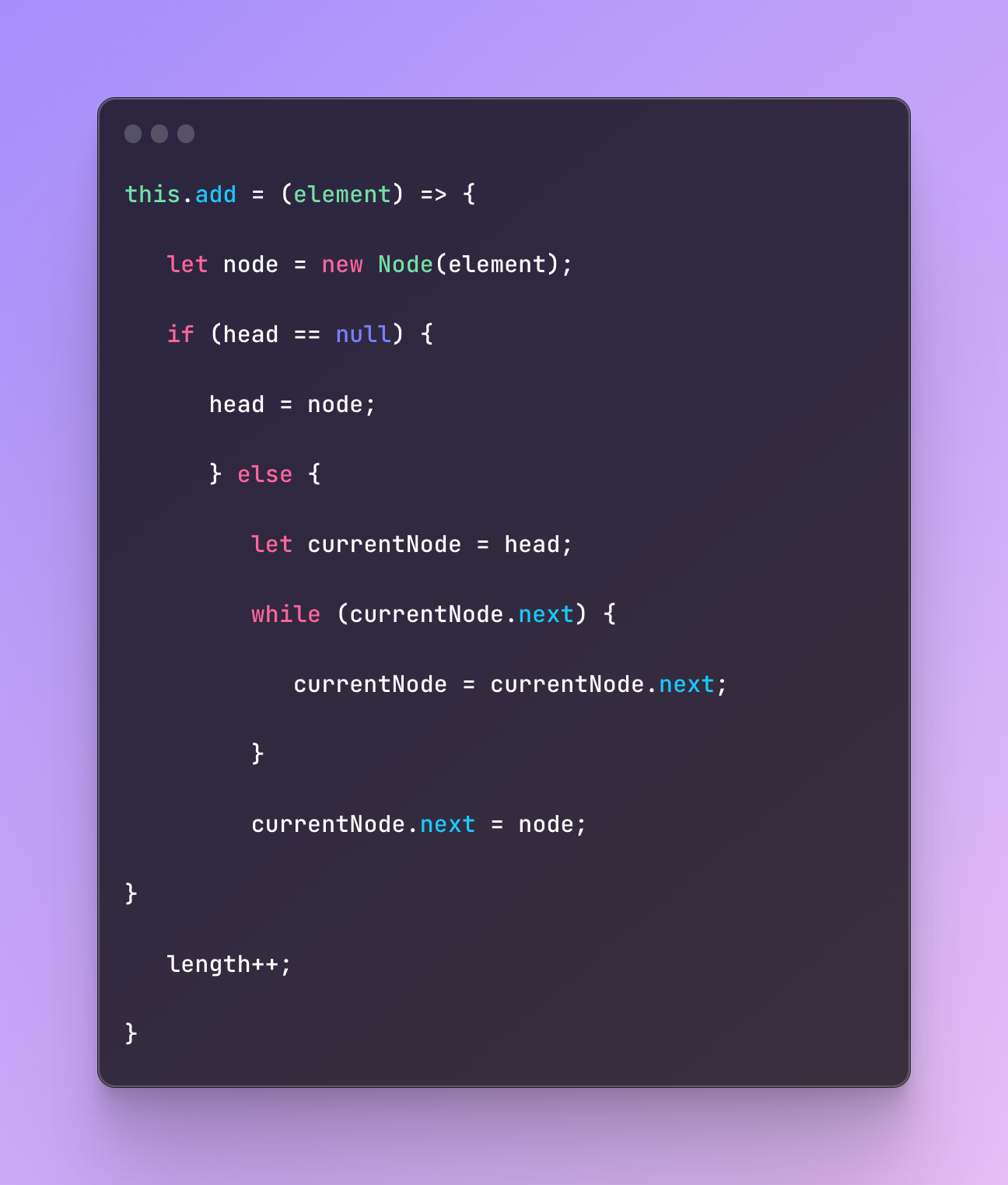
Time to implement the add element function where we create a new node with the node function, check whether there already is a head, and if not the added element will be a head, other Wie next node will be this added element. In the end, we increase the length of the list.
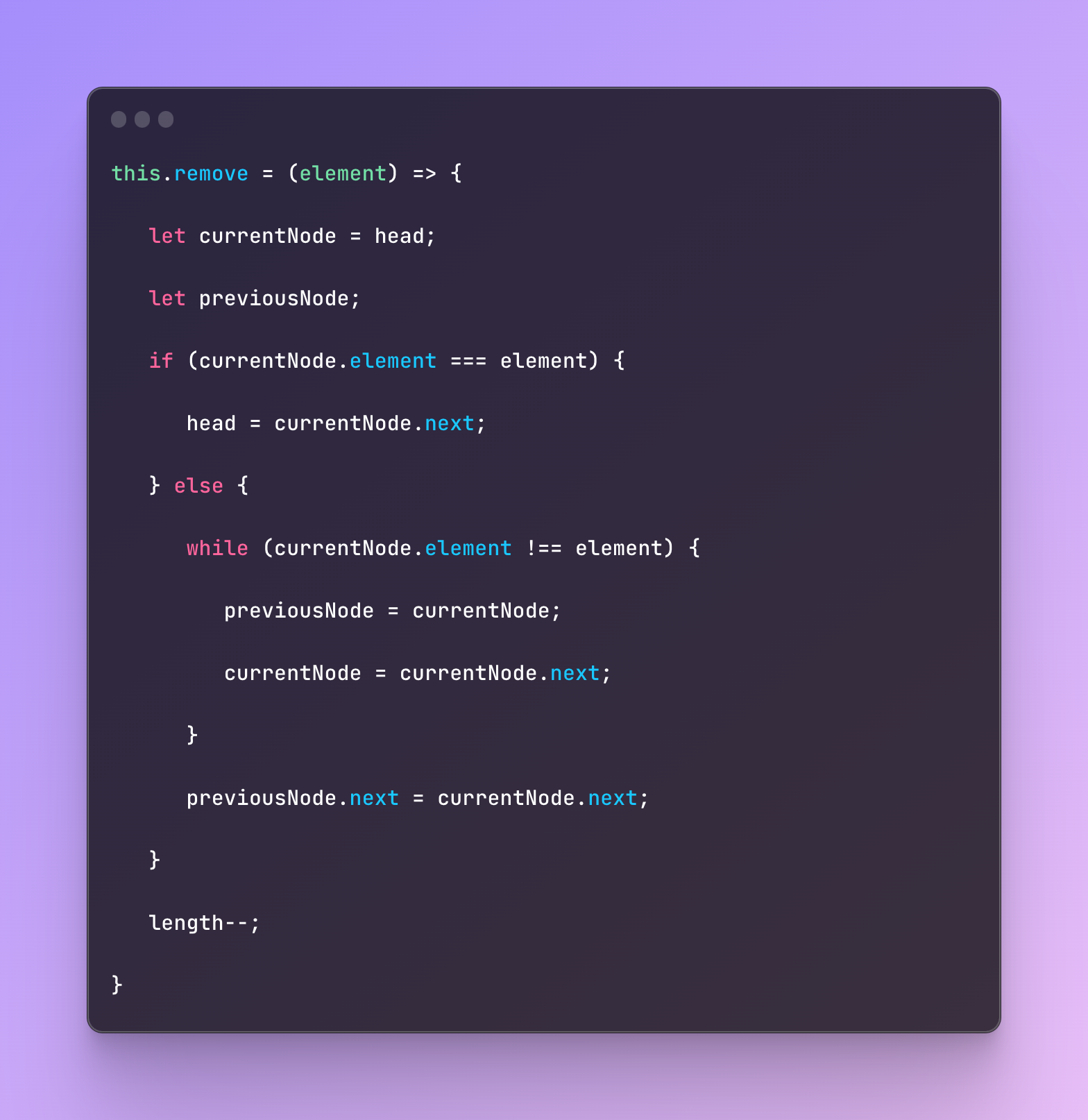
Next, we are going to implement a function that removes an element where the logic is almost the same.
Linked lists also have a method that can add elements to the specific position which is a big plus compared to many other data structures. To implement that we simply use indices.
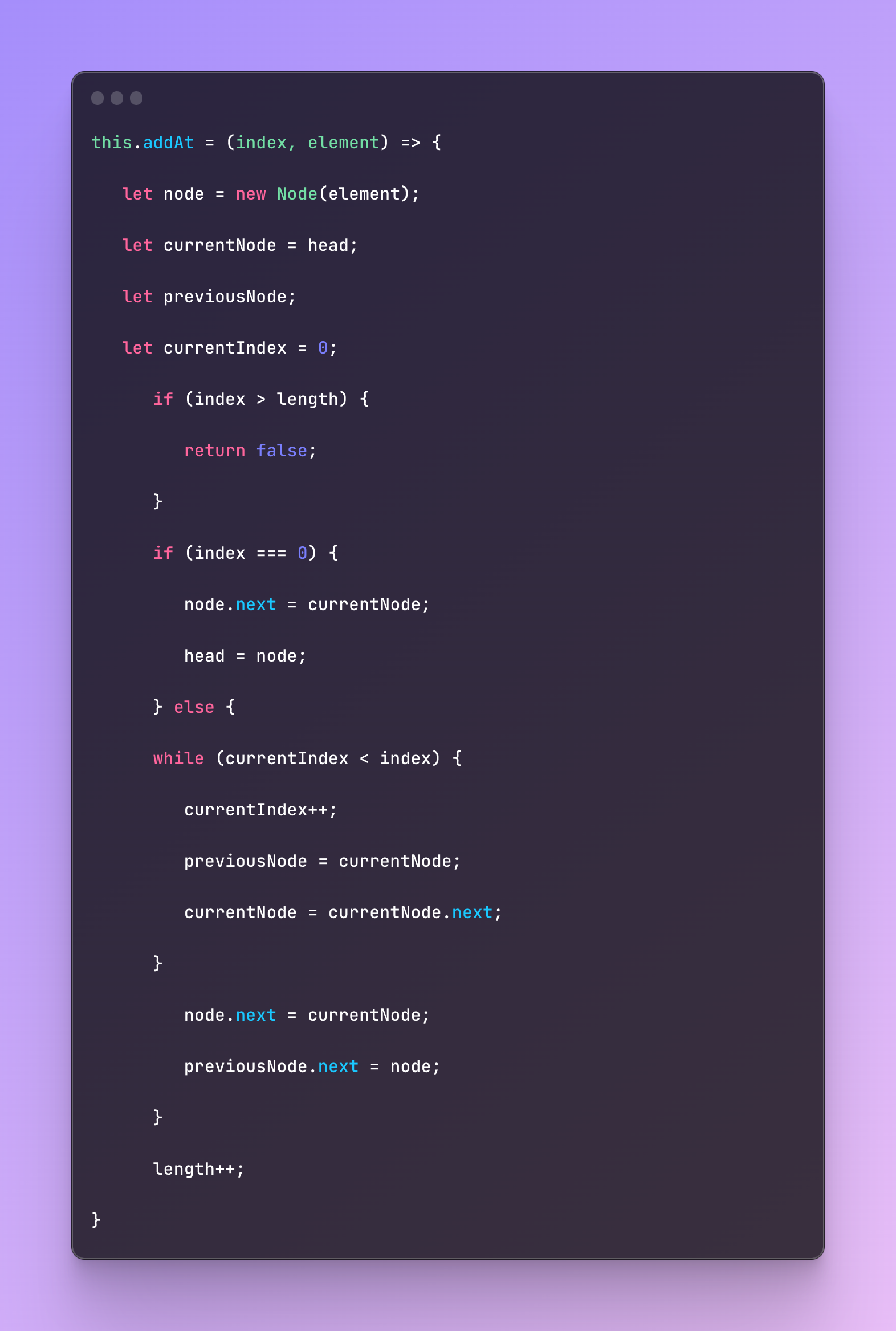
And now the removal of the element from the specific position.
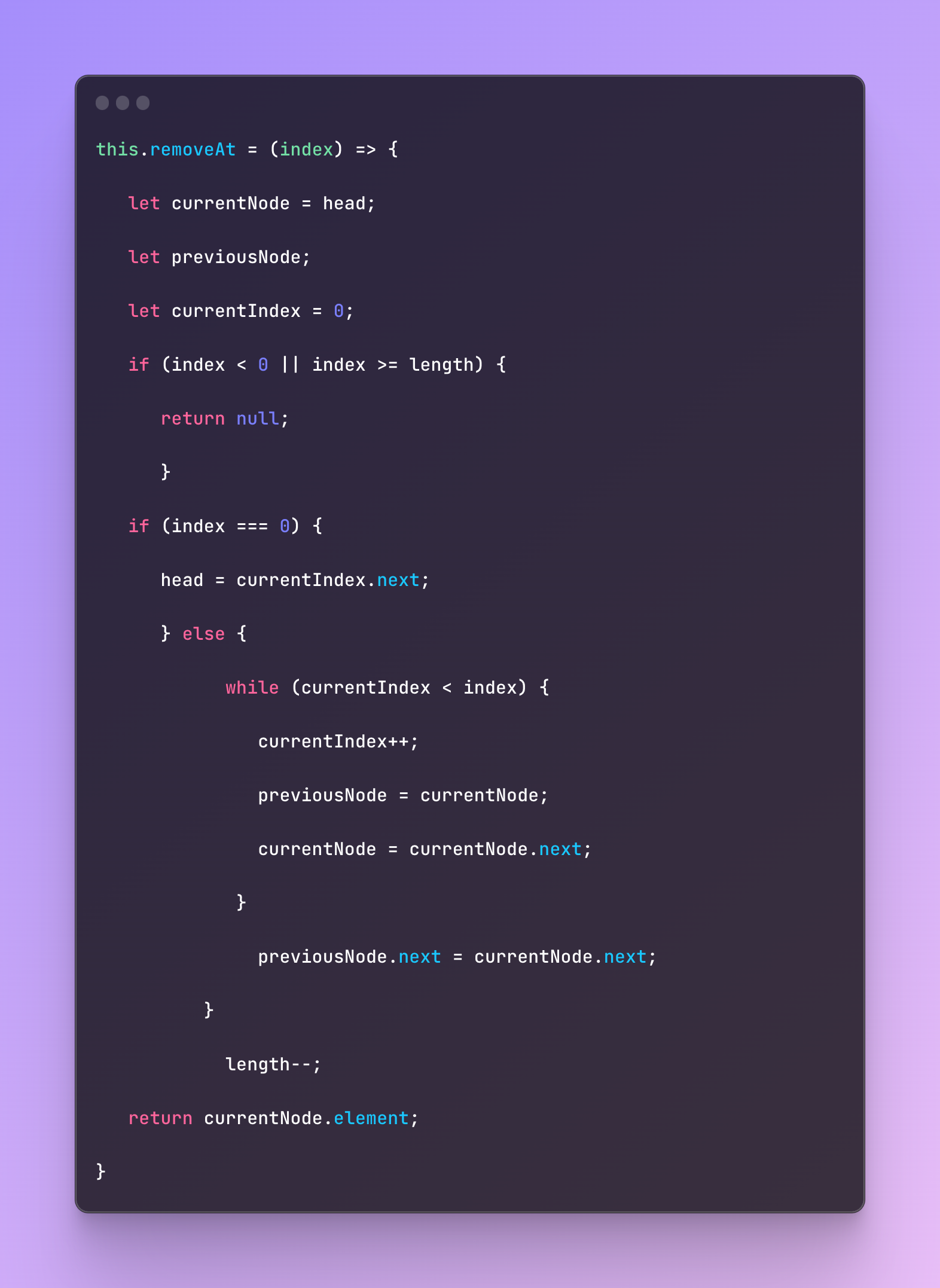
There are also many other methods however we just cover the basics right now and not going to go into more detail about linked lists.
#7 Trees
A tree data structure is a type of parent/child relationship between data. If you are already familiar with HTML it’s something similar where we have DOM consisting of nodes that have a parent or a child. Or a simple real-life example of a geological tree that consists of parents and children. But it’s more. Visual side because the functionality is a little different which I will explain very soon.
The main, the upper node is called the root and the others that come from it are children. Nodes that do not have any descendants, no children, are called leaf nodes. Trees also have a height that is determined by the number of parent/child connections.
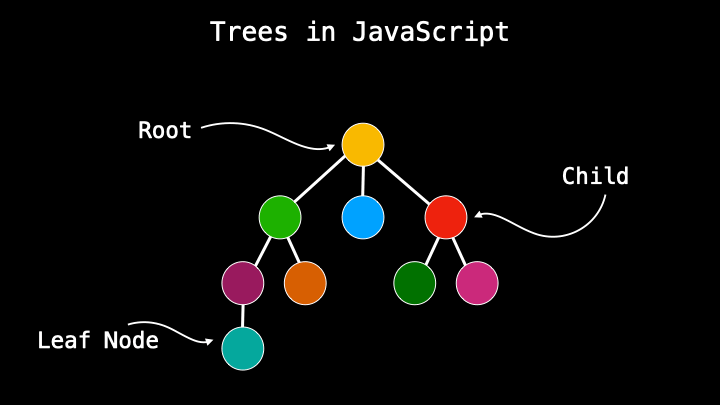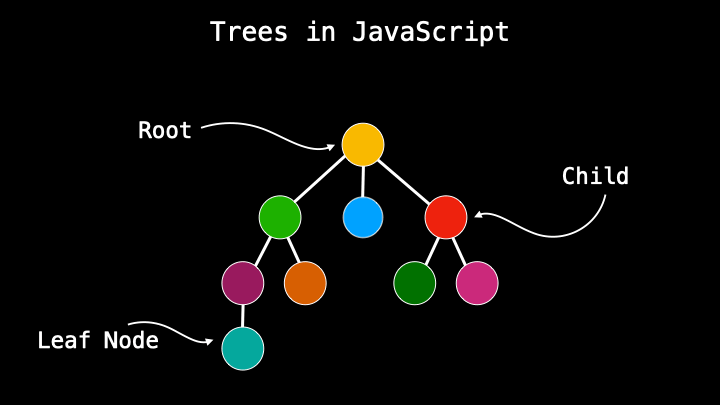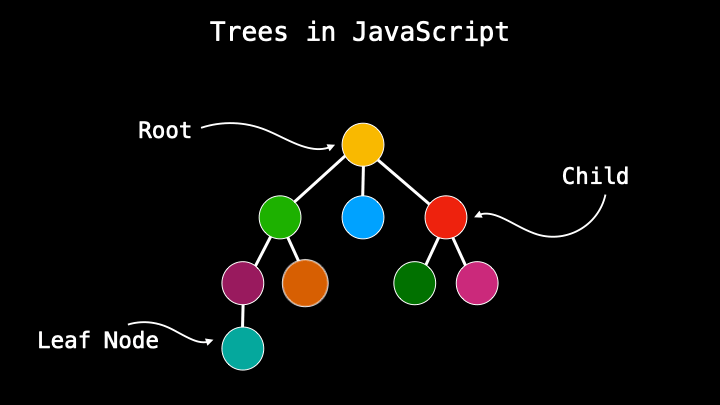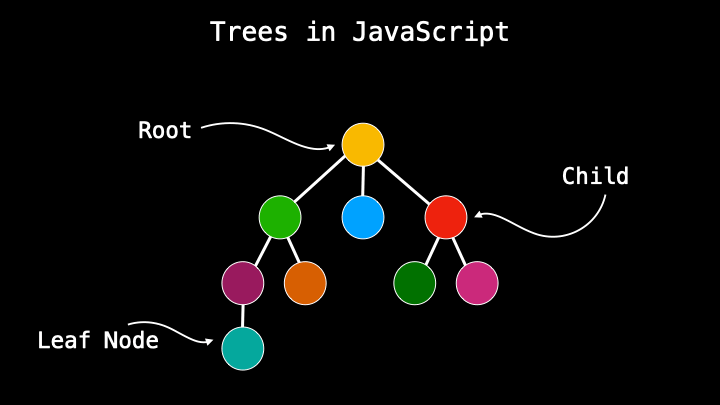
The connection flow in trees works from part to child only, not from child to parent or between siblings. This is one of the biggest differences compared to other data structures which visually also look like trees.
We can have different types of trees but the two most common types of trees are Binary trees and Heaps.
Binary trees
In a binary tree, each node has a maximum of two children and it’s often useful in searching, where we call this binary tree a binary search tree. Each value that comes from the left side node must be less than its parent’s value and on the left side, each descendant must have a bigger value than the parent.

This type of order makes it an ideal structure to search for things since you know that on the left value is less and on the right value is greater. So you can compare things faster and discard the ones you don’t need.
Let’s implement BTS (binary search tree) with JavaScript classes as yes, you guessed it, there is no actual implementation of it so we have to do it ourselves.
First, we will create a class for each node.
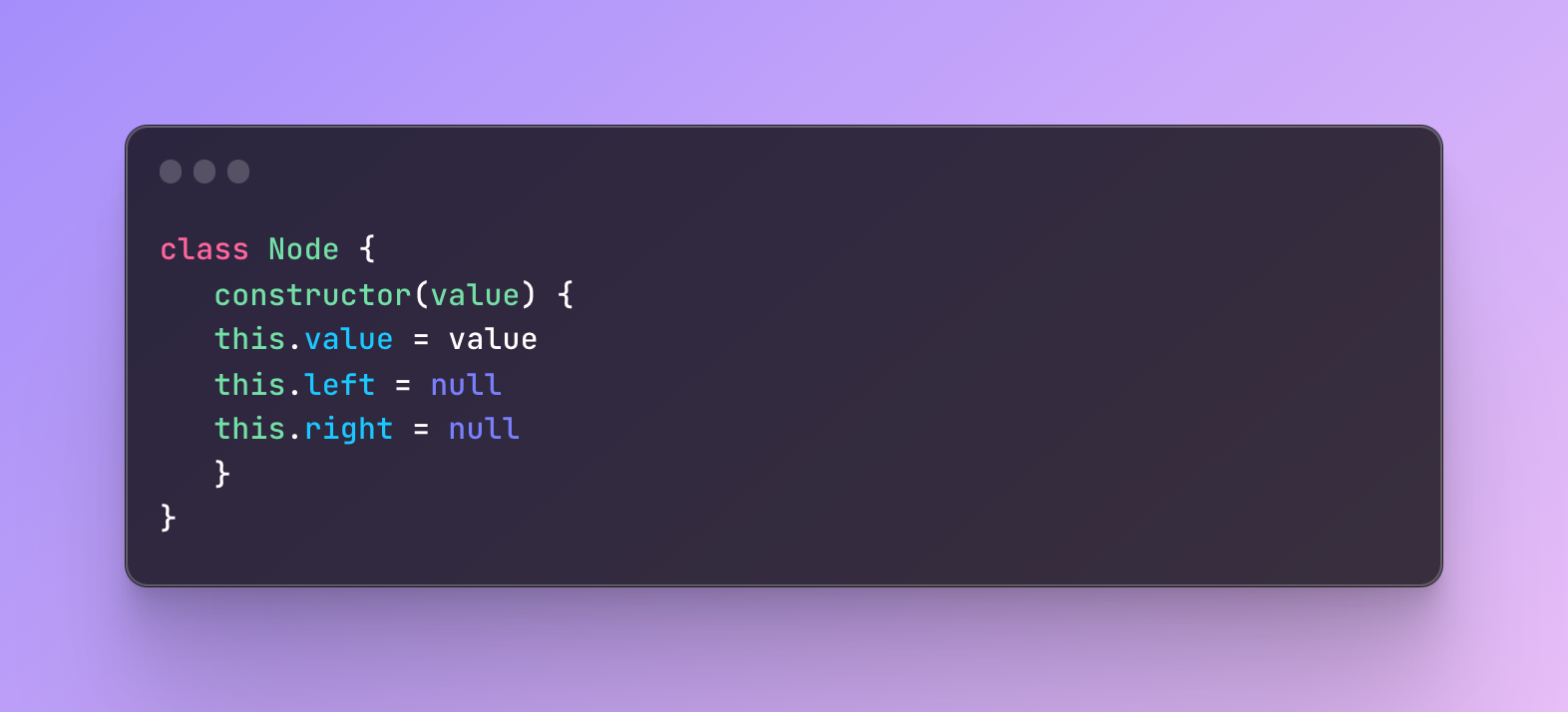
Next, we create a class for the BTS with only one property for the root node.

And finally, we can start implementing different methods like inserting some data which takes the value and inserts it into a corresponding place.
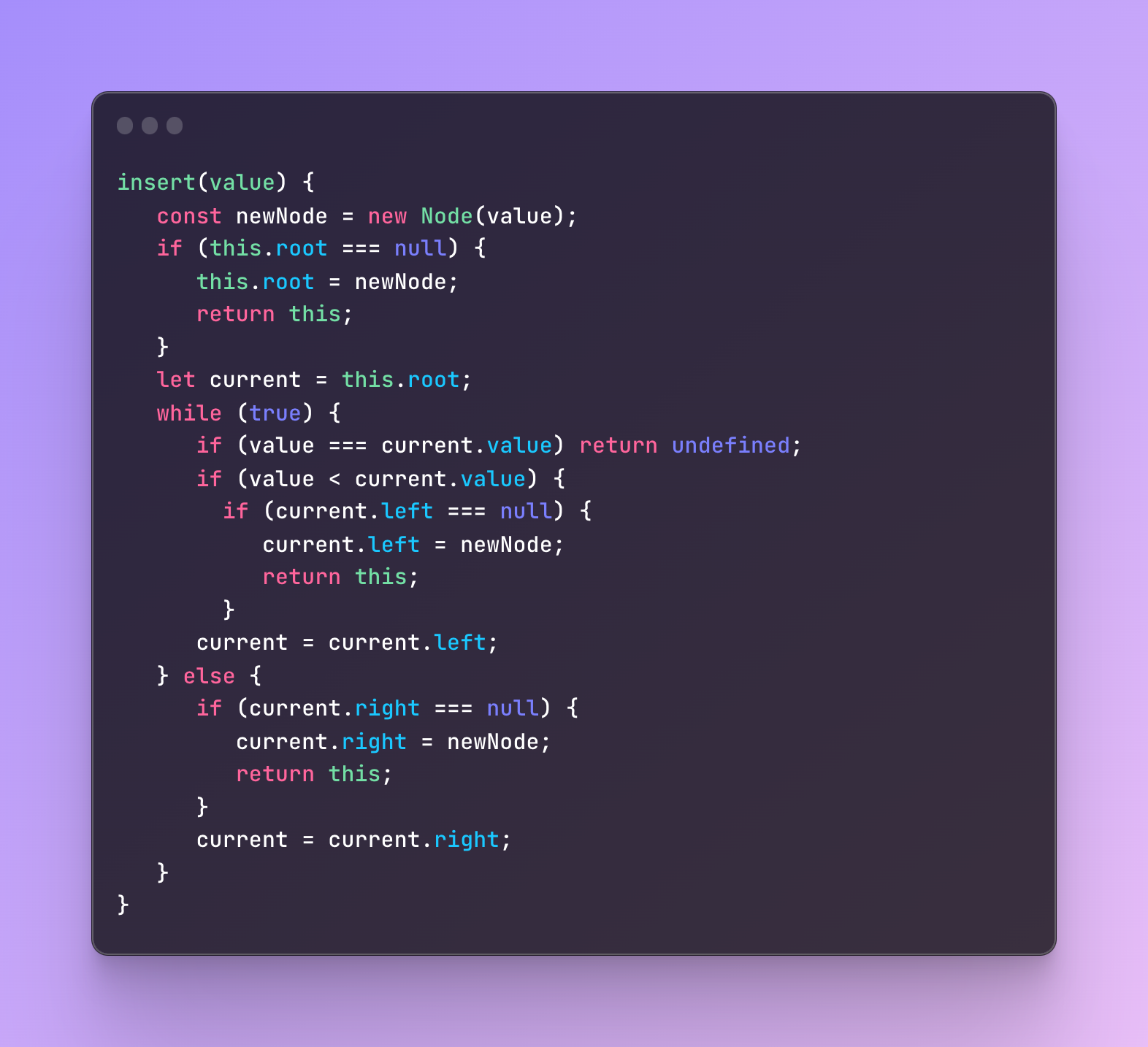
Next, we can create a method that finds the value we need.
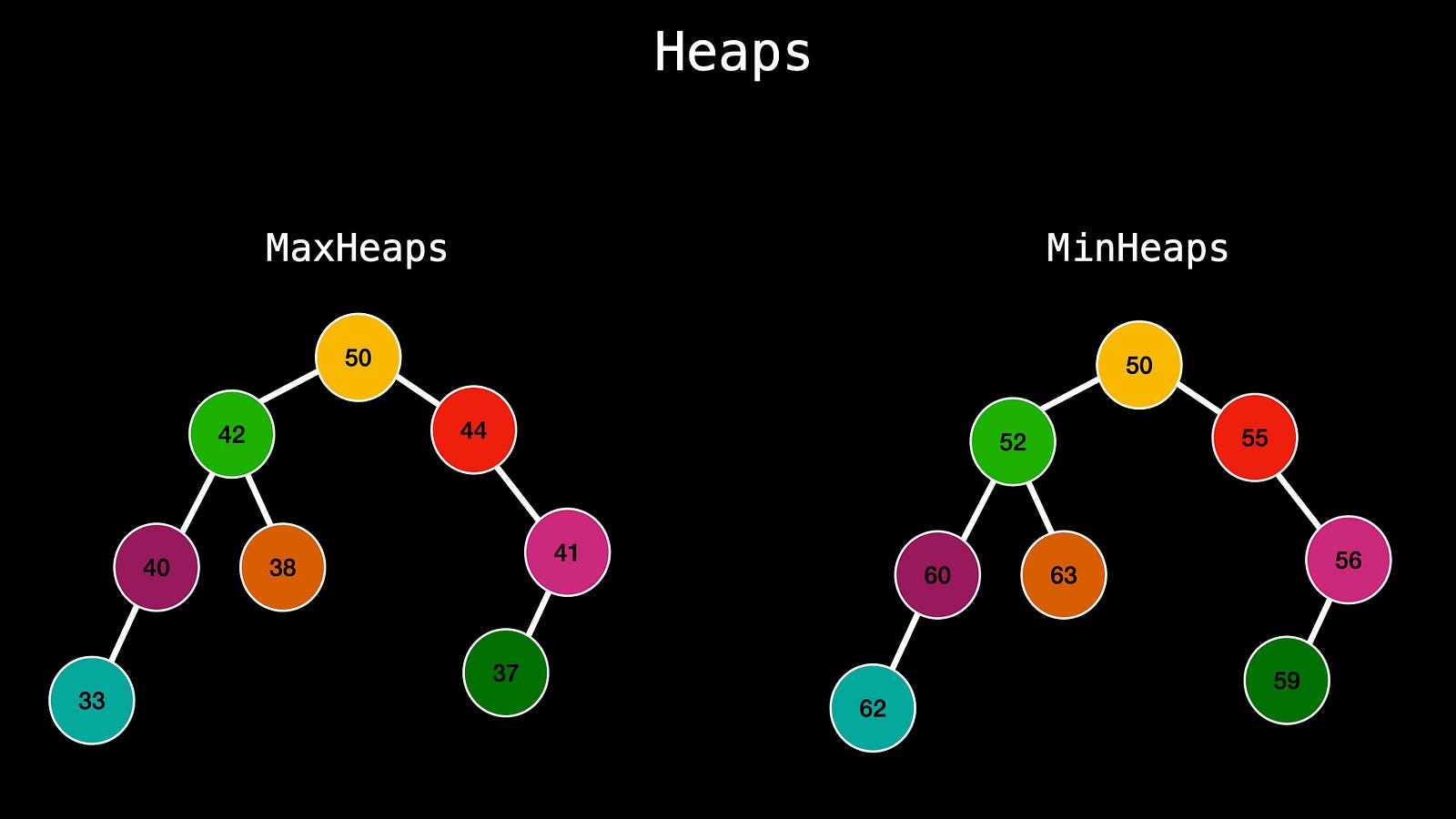
Heaps
Heaps are another type of tree that has two sub-types — MaxHeaps and MinHeaps.
In MaxHeaps the parent node is always greater than its children and in MinHeaps the parent node is always lower. So in this case there is also not much connection between siblings and it’s only a parent/child relationship.
7️⃣ Graphs
Graphs are another data structure which is also known as networks as its set of nodes that have linkages or edges. A very simple real-life example of a graph is routes that we use in navigation apps or maps, for example.
Another good example is recommendations, when let’s say on Facebook or Instagram you receive account recommendations that you might be interested in as there is a link between your friend with others and the account you like with other accounts. It’s all linked.
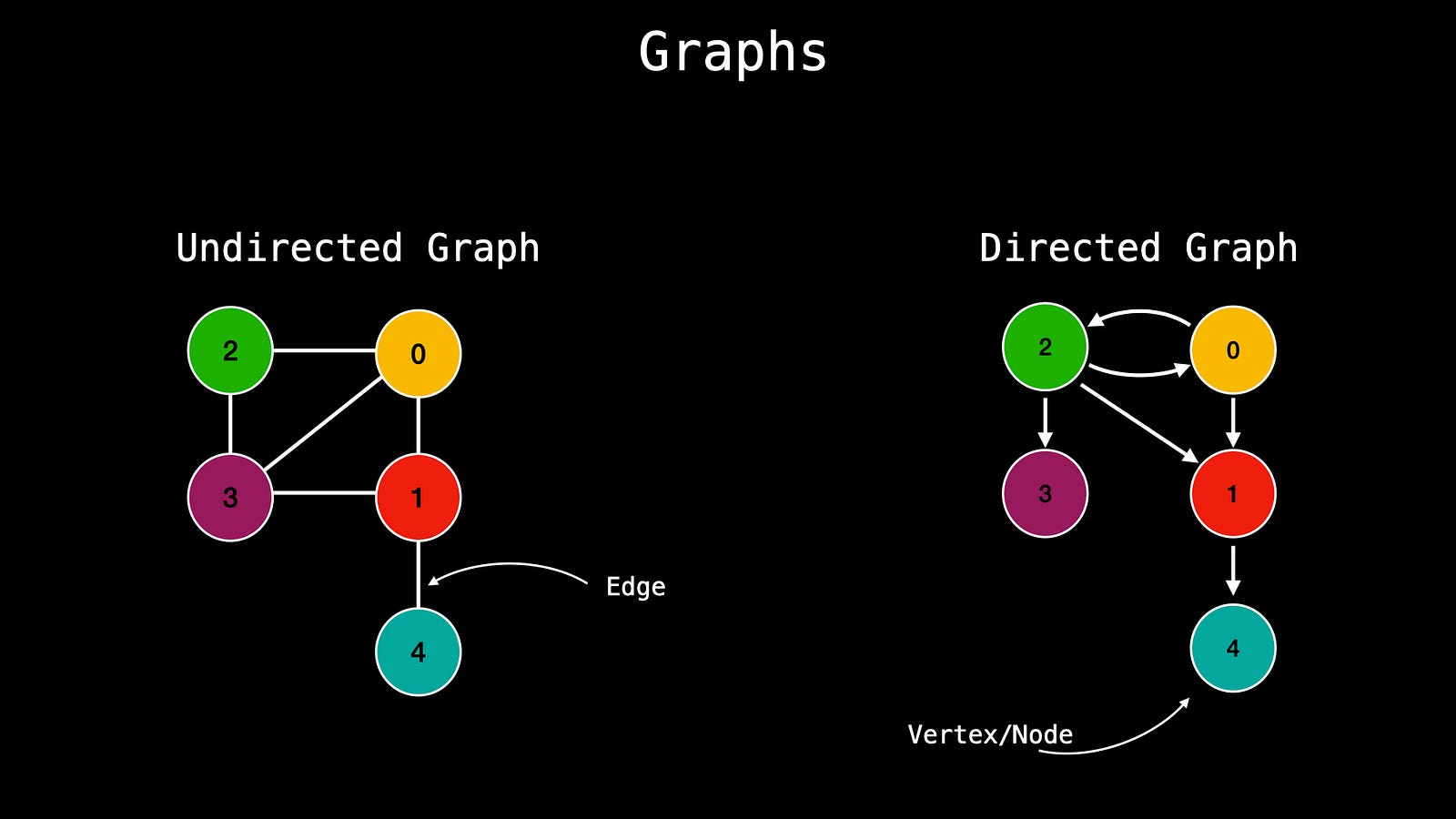
Graphs can be divided into two groups — directed graphs and undirected graphs. The group depends on the direction of the linkage. In any graph, compared to trees we don’t have any root nodes, leaf nodes, head to tail. There is a parent/child relationship and different nodes are connected anyway.
A graph is undirected when we do not have any specific direction of the connection between nodes. In the image above you will see that the undirected graph doesn’t have an arrow that points to a specific direction. In such cases direction can be both ways, for example, a node with the number 2 can have a direction to 0, and 0 can have a direction to node 2.
A graph is directed when there is a specific direction of the connection meaning that if we have a direction from one point to another and there is no pointer back, means that we cannot have the reversed direction.
When it comes to graph creation we have two ways to represent a graph — an adjacency matrix or an adjacency list.
Adjacency matrix
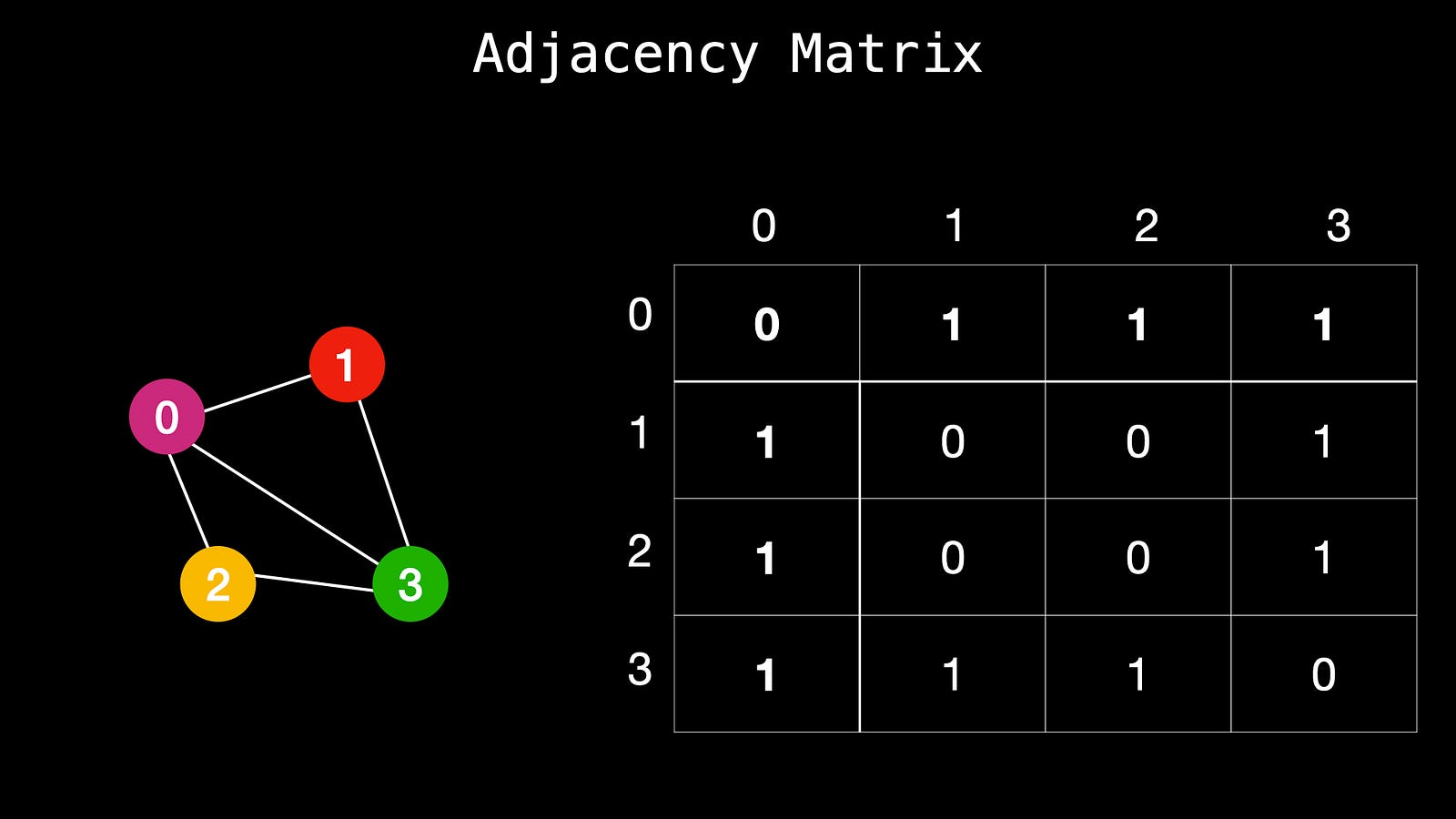
An adjacency matrix is a two-dimensional structure of nodes. It’s something like a table with rows and columns which are nodes, and the value inside the cells represents a connection between these nodes. The values can be 0 or 1. If the cell value is 1 it means there is a connection if it’s 0 then there is no connection.
This is how we usually write it
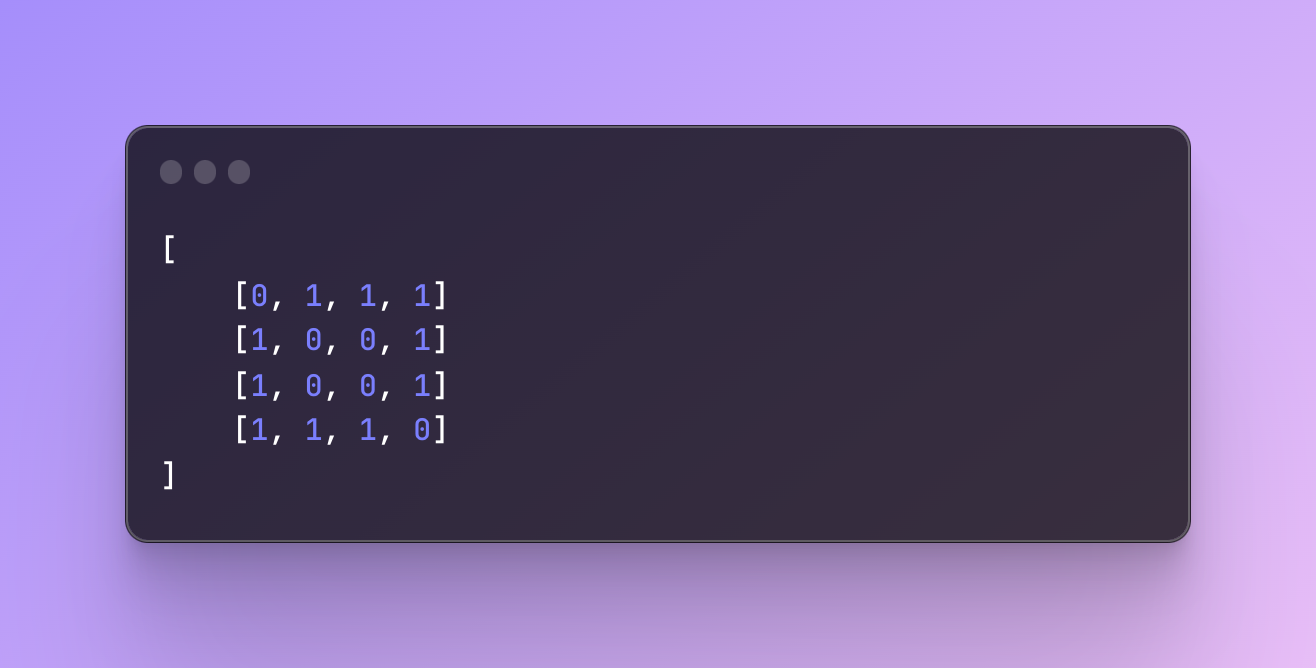
And this is a better visual representation of the connection between nodes. Each letter outside the table represents the node. Node 0, node 1, and so on. The 0s and 1s represent the connection that exists. Where there is 0 it means these nodes are not connected and where you see 1, means that they are connected.
Adjacency list
An adjacency list however has a key/value pair structure where a key is a node and values are connections.
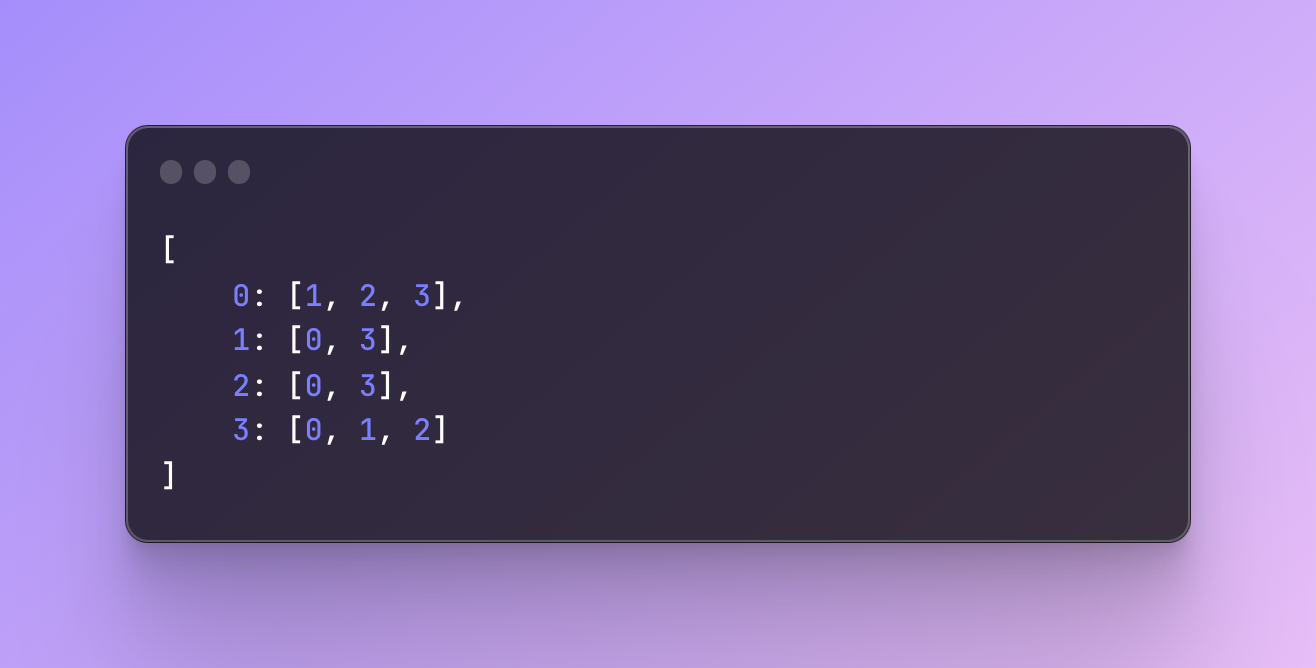
Looks very similar, right? What happens here is that the array in the value includes the value of the node that the node in the key is connected to. So, the node with 0 contains an array of nodes that have values 1, 2, and 3.

The main difference is that lists are usually more convenient when it comes to removing or adding nodes as they are grouped in one place but the matrix is better when you need to query across the connection of nodes.
Searching through graph
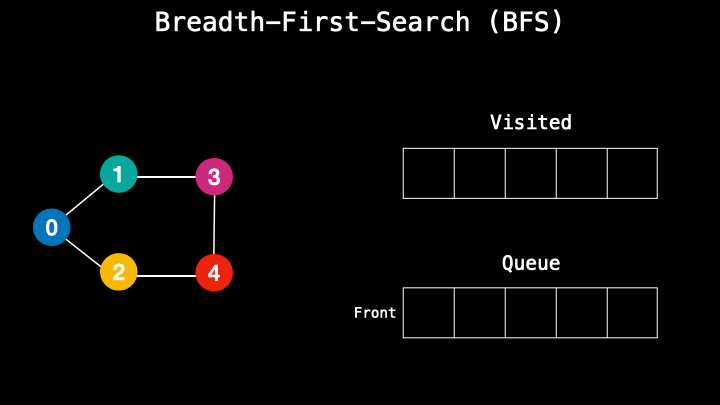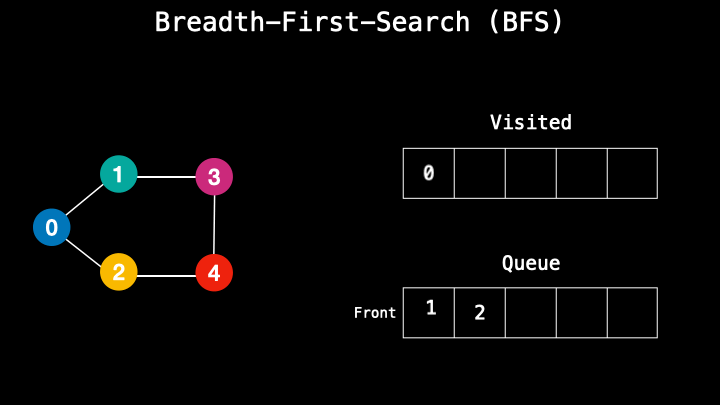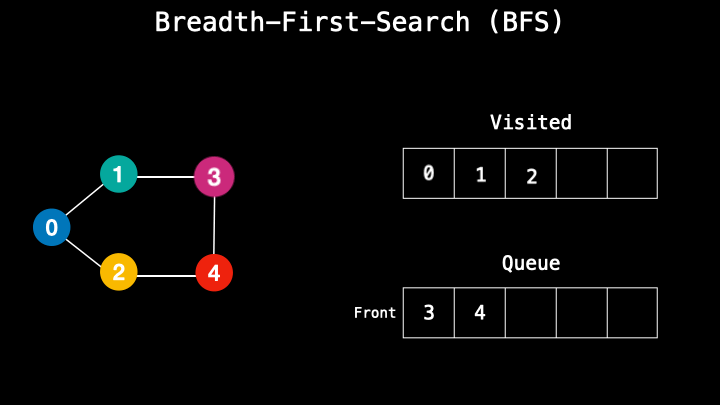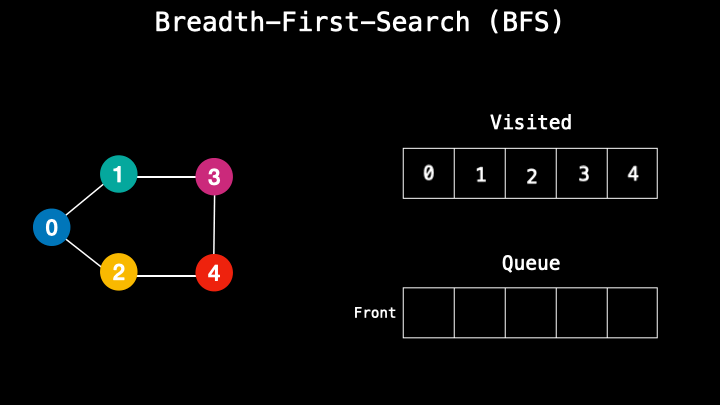
When we search for something inside the graph, it’s also called querying. To query for nodes in JavaScript we can use two methods — breadth-first-search (BFS) or depth-first-search (DFS).
A breadth-first-search starts a search from the top node and has a node-based search. It’s similar to the queues first in first out method. So it takes one top node, then goes to its adjacent nodes and stores them in a queue. When the first node is done, then it moves to the next one in the queue and does the same, visiting its adjacent nodes. So the top node is the first to enter the process and the first to leave the process.
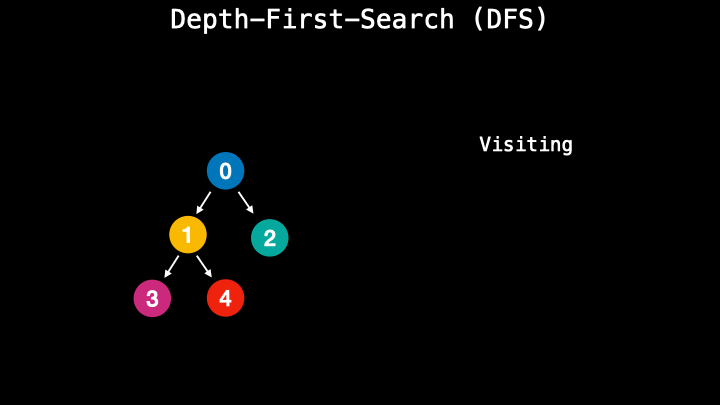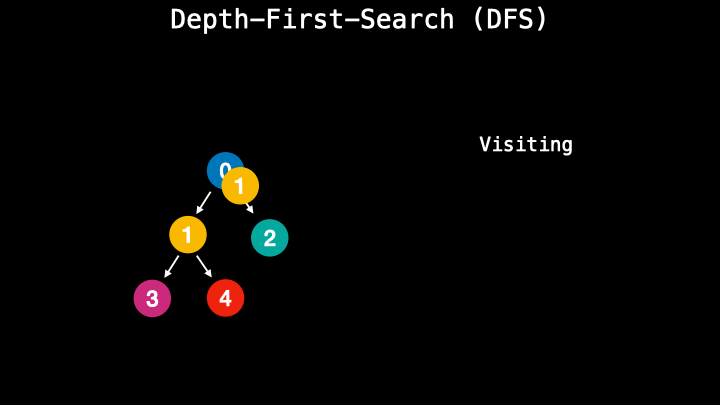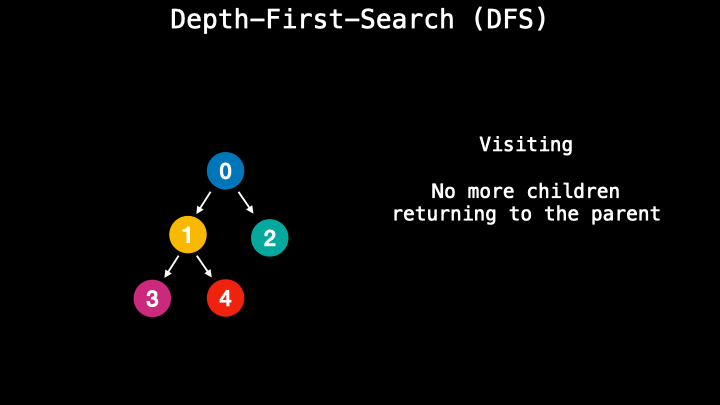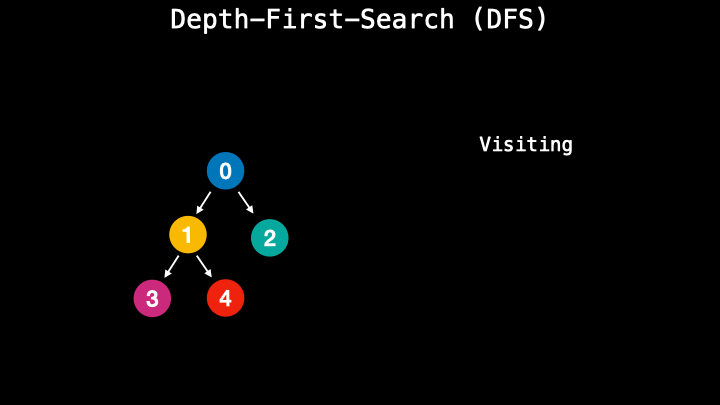
A depth-first-search however performs the process similar to stack and uses the last in-first-out technique. During this process, it visits the nodes along the path. So it chooses one path and follows it until the end. When it reaches the leaf node it goes up and checks if there are other children nodes. If not, it goes up more time. This type of method is usually faster and requires less memory.
Conclusion
Congratulations! If you made it this far even if it took you several days or weeks that is awesome and a great start to getting to know data structures. I did miss many aspects of different data structures and didn’t explain each of them in even more detail because I think it would be very hard to understand so many things at the very start of your JavaScript journey. I wish someone told me I should start learning about data structures a little bit more as eventually, you will stumble upon them at the later stages and if I knew a bit earlier it would be much easier. I hope this will be a good start for you as a beginner JavaScript developer or just a developer in general.